Pressure Project 1: Fortune Teller
Posted: September 22, 2017 Filed under: Zach Stewart Leave a comment »My fortune telling system put visitors through a silly yet engaging interface to reveal to them some their deepest, darkest, most personal fortunes…. or, more than likely, just an odd, trolling remark. From the beginning of the project I wanted to keep the experience fun and not too serious. I wanted to keep some aspects of the stereotypical fortune telling experience but critique the traditional experience in that the questions I ask and the final response have essentially nothing to do with each other. It was also important for me to remove the user from the traditional inputs of the computer (i.e. the keyboard and the mouse) to create a more interactive experience.
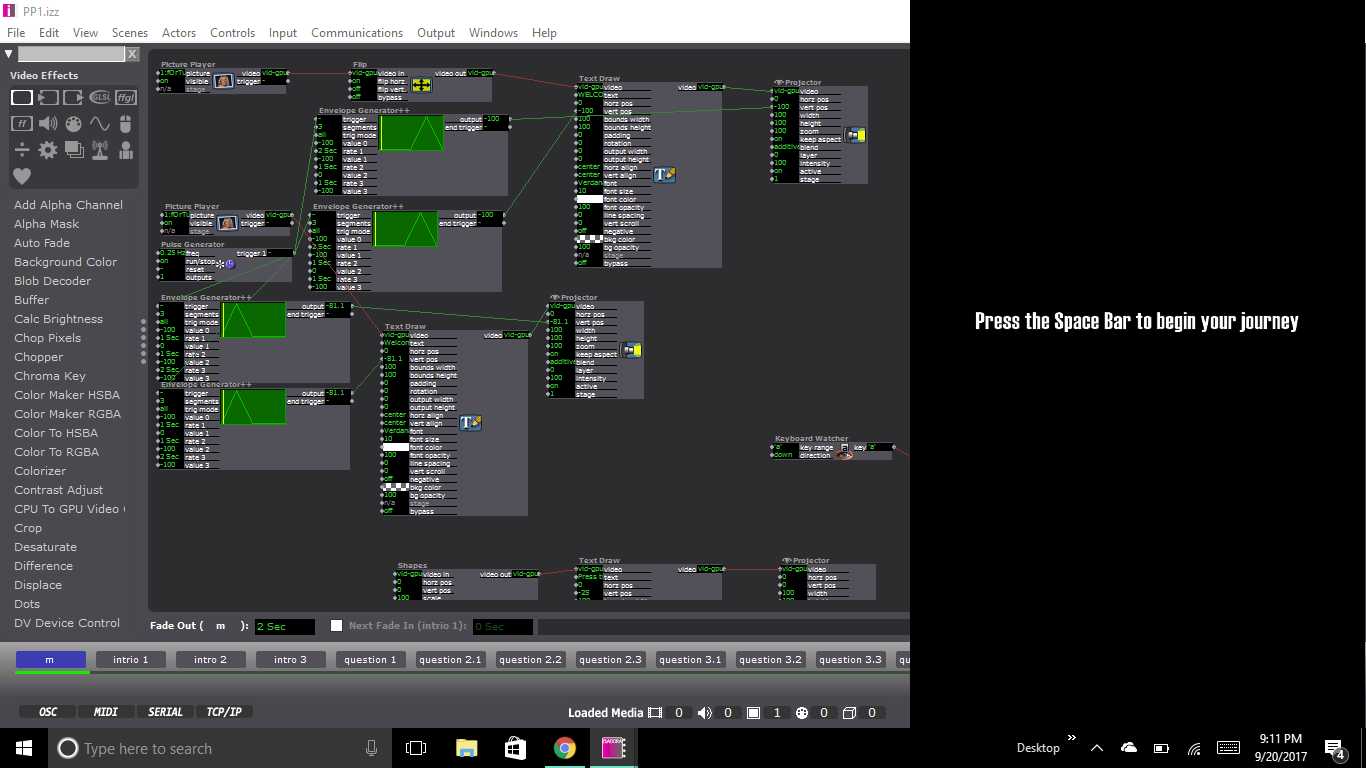
My system started by prompting the user to begin their journey by pressing the space bar (the only time they used the keyboard during the experience) which took them through several scenes that set the up for what was about to happen. The purpose of these scenes wasn’t to take in user input but set the mood for the experience. The slides were simply just text that had a wave generator applied to its rotation input to give the text a more psychedelic, entrancing feeling that falls in with the theme of the fortune telling experience. The idea here being to create some predetermined conversation that would carry throughout the entire project.
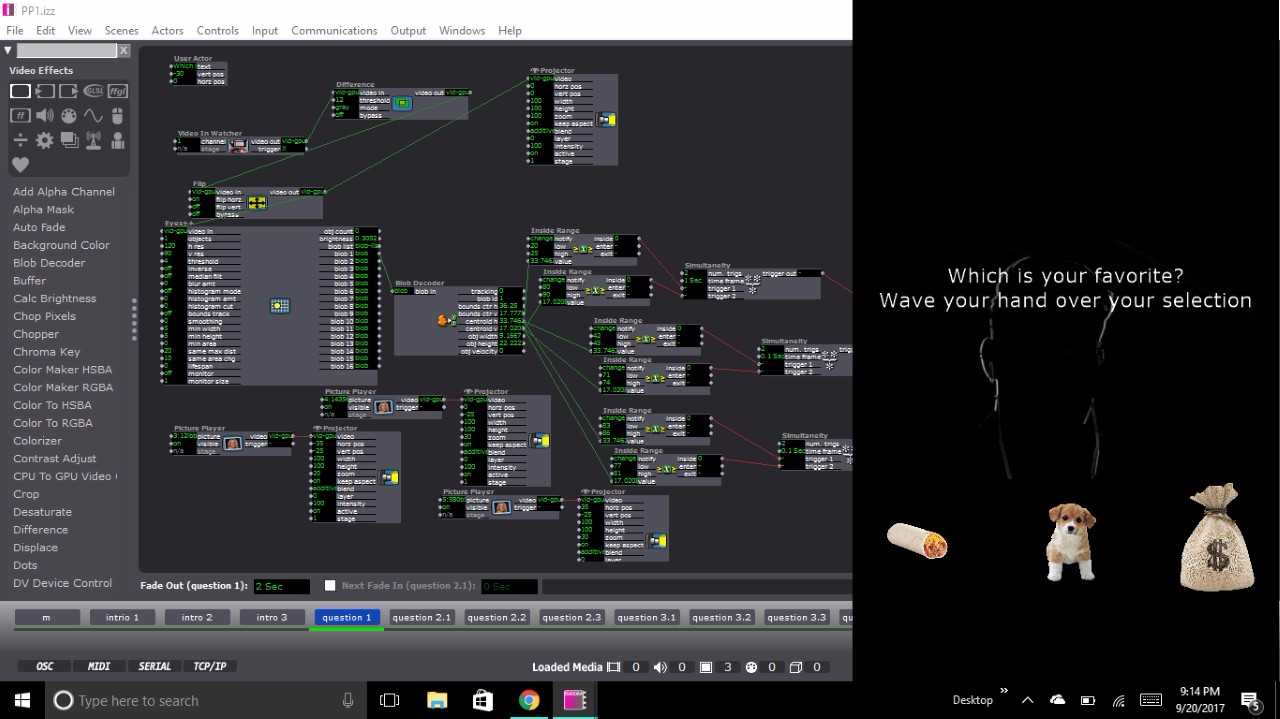
Once through the initial scenes, the user was introduced to the first scene with a question which had 3 possible responses. On the scene, the top part of the screen was devoted to the text. On the lower portion were 3 icon representing responses to the question. In the background of the scene is the projection of the user. The projection is using the video input from my computer’s web cam and then running it through the difference actor to calculate the movement of the user. The output of the difference actor was also plugged into an eyes++ actor which tracked the movement of the user through the blob decoder actor. To respond to the question the user was prompted to wave their hand over the icon that matched with their answer. The scene would then jump to the next scene that corresponded with the answer. This happened due to the inside range actor that were placed over each icon that watched for the blob’s movement over the actors. The scene would change once the x and y coordinates of the blob were inside the range prescribed by the inside range actors.
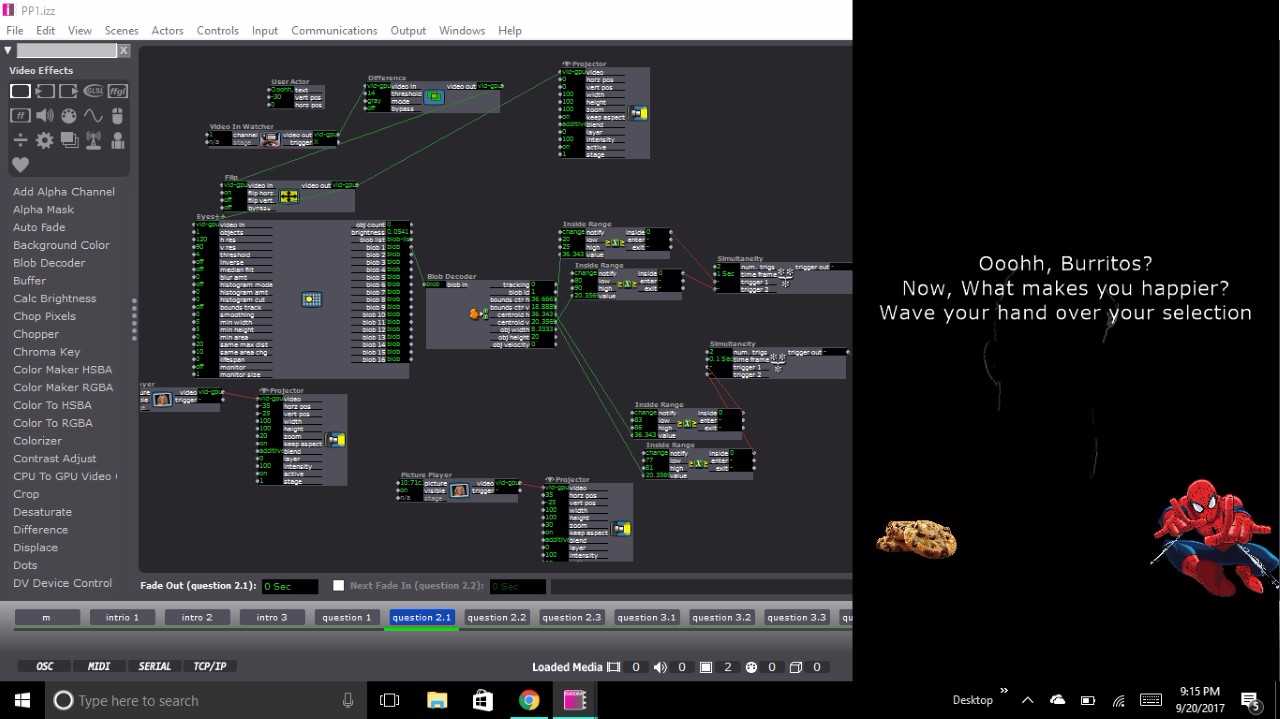
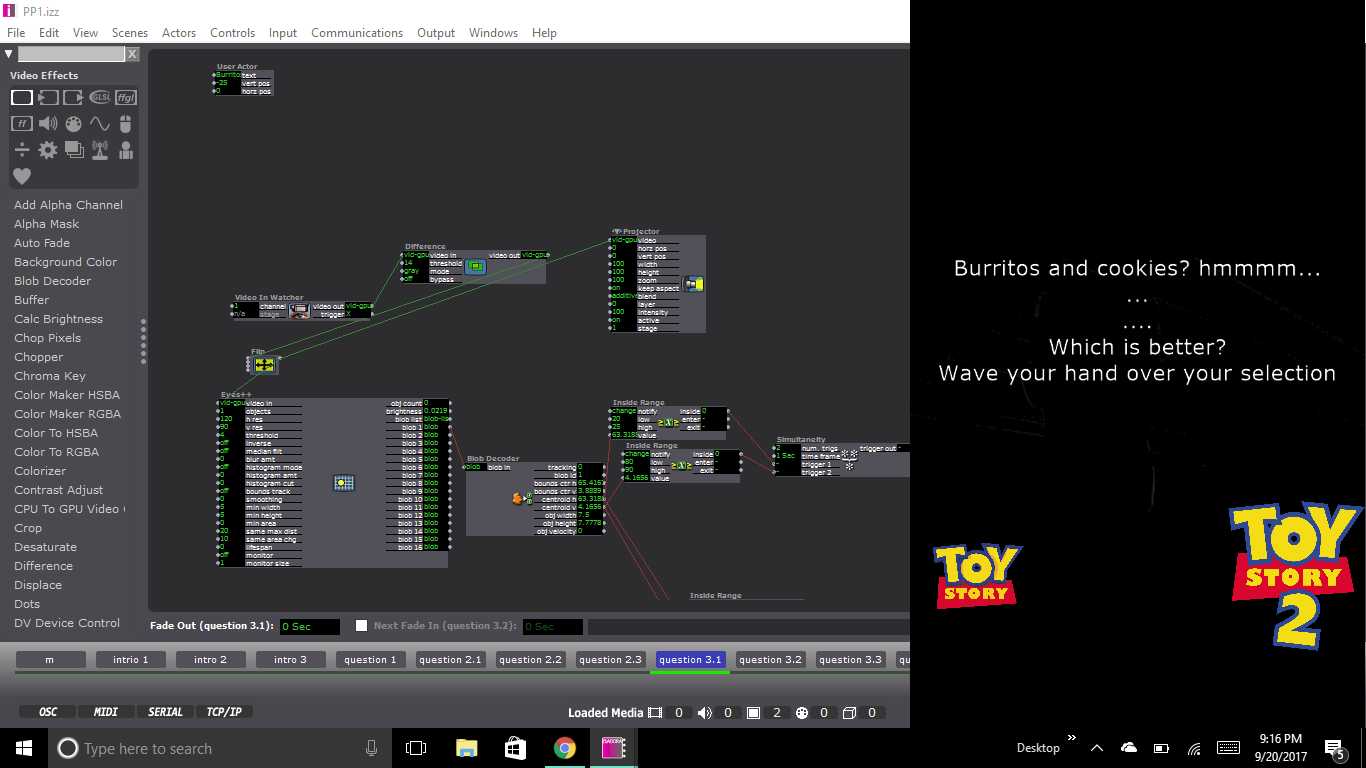
This set up for the scene continued throughout the remainder of the project. Each set of questions that followed tried to keep up with the user’s inputs with text presented at the top of each scene. The text continued the conversation that was started at the beginning of the presentation. After the first question, depending on the user’s choice, they could have been brought to any one of three scenes with a question featuring two possible answers. From there, the user was then directed to a third question with another two potential answers. The third question for all possible question paths was the same, but it appeared on six separate scenes as to still be considerate of the user’s previous inputs and the user’s answer to the question. From the last question the user was then fed into a scene containing 1 of 6 possible fortunes. And that was it!
During the presentation of the system, I ran into some tricky bumps in the road. The big one being that the system would skip scenes when users would wave their hands too long over an icon. Additionally, and confusingly, it would in some cases not respond after several seconds of violent waving by a user. When the system’s tolerance was calibrated it was calibrated in a lot of natural light which could have given rise to discrepancies when the system was then turned on in the computer lab which is only lit by artificial light. The system could be fixed using several alternative methods. The first being a trigger delay for when moving from scene to scene. This would prevent that eyes++ actor from prematurely recognizing inputs from the user. The second being a stricter calibration of the eyes++ actor. In the actors inputs you can control size of the recognized blob being tracked and the smoothness of its movement. Both of these inputs would have given greater tolerance to user’s movement. The last solution may have been to consider a different form of input that used a more sensitive camera or Leap Motion.
Additional improvements could be made around how the system interacts with user and the type of outputs the system produces. After watching some of the other presentations it was very clear that my system could have benefited from the introduction of sound. The element of sound created another level of thematic experience that could have played up the concept of my goofy fortune telling experience. The second being the idea of the system looping back to the beginning. After every user finished their interaction the system had to manually prompted back to the being scene. A jump actor could have easily fixed this.
I feel like I could say more, but I should probably stop rambling, so here is my project, check it out and enjoy!
https://osu.box.com/s/dd6sopphqnxa5uu8cgjboa0xzsam2u0r