Final Documentation Jonathan Welch
Posted: December 20, 2015 Filed under: Jonathan Welch, Uncategorized Leave a comment »OK I finally got it working.
The Master Patch
Eyes++ Tracking the viewer sending data to the “Emotion Matrix” that sent the character’s response to the “Player Controller”, which triggered the Players. The background interlacing was done in the “Background”.
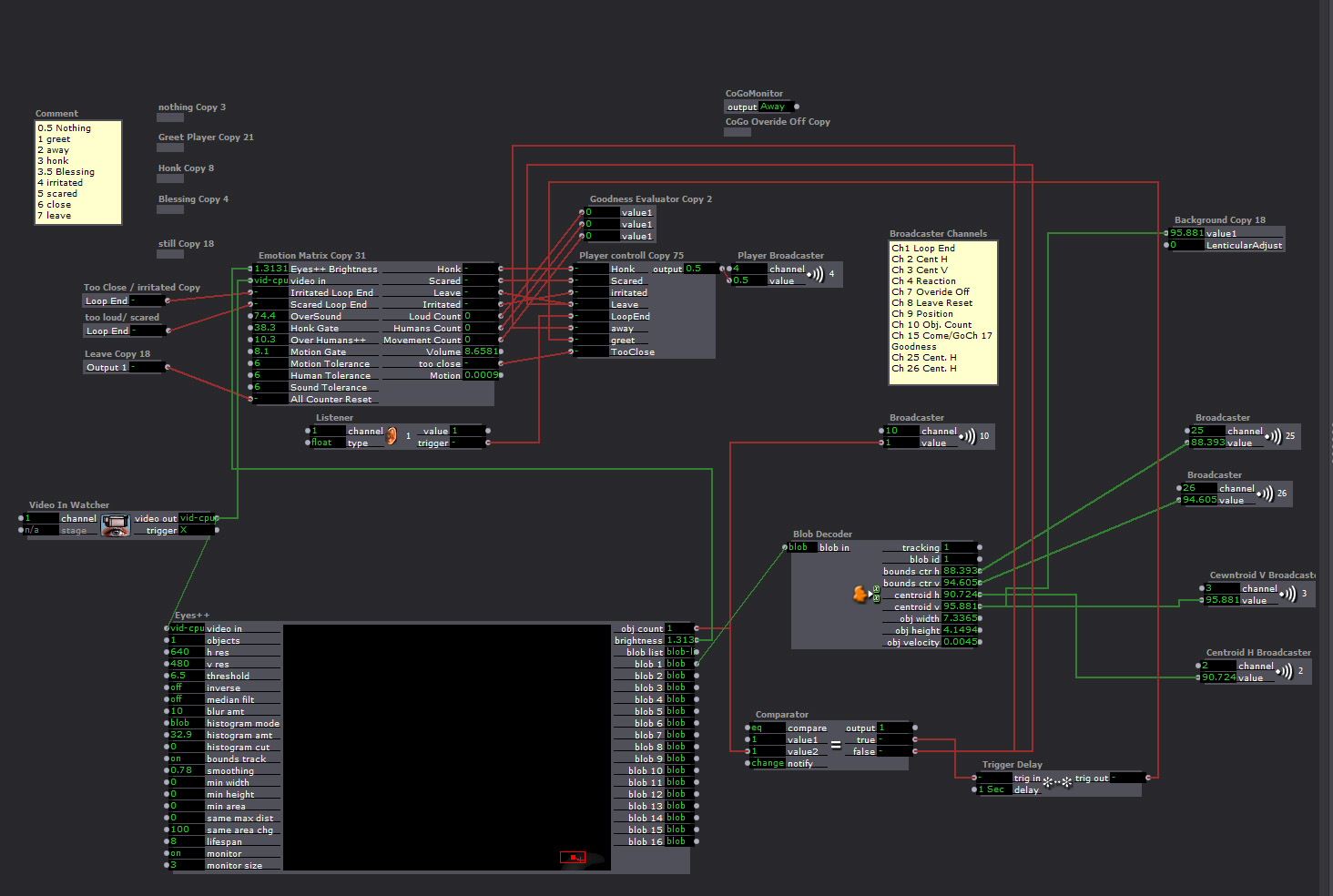
This is the “Response Player”
There were 9 Responses (6 different animations, 2 actions that generated the same response, a still frame, and blank/away response). The players were very similar, but the “Leave” and “Greet” players had a broadcaster that toggled the character’s Here/Away state so noises when no one was around wouldn’t trigger the honk response.
The responses were:
1. Leave (triggered if no one was there, or you pissed him off)
“Honk” walk off camera off and subtitles read “Whatever Mammal”
2. Greet (triggered when someone arrives, the “Blob Counter” was 1)
Walks Up to the camera
3. Too Close
Honks and the subtitles read “You are freaking me out human”
4. Too Loud
Honks and the subtitles read “Are humans always this loud?”
5. Too much motion
Honks and the subtitles read “You are freaking me out human”
6. Too many Humans
Honks and the subtitles read “You are freaking me out human”
7. Honk
Honks and the subtitles read “Hey”
8. Blessing
Honks and the subtitles read “May your down always be greasy and your pond go be dry”
9) And Pause or Away (still frame, or blank frame depending on weather it the state was “Here or Away”)
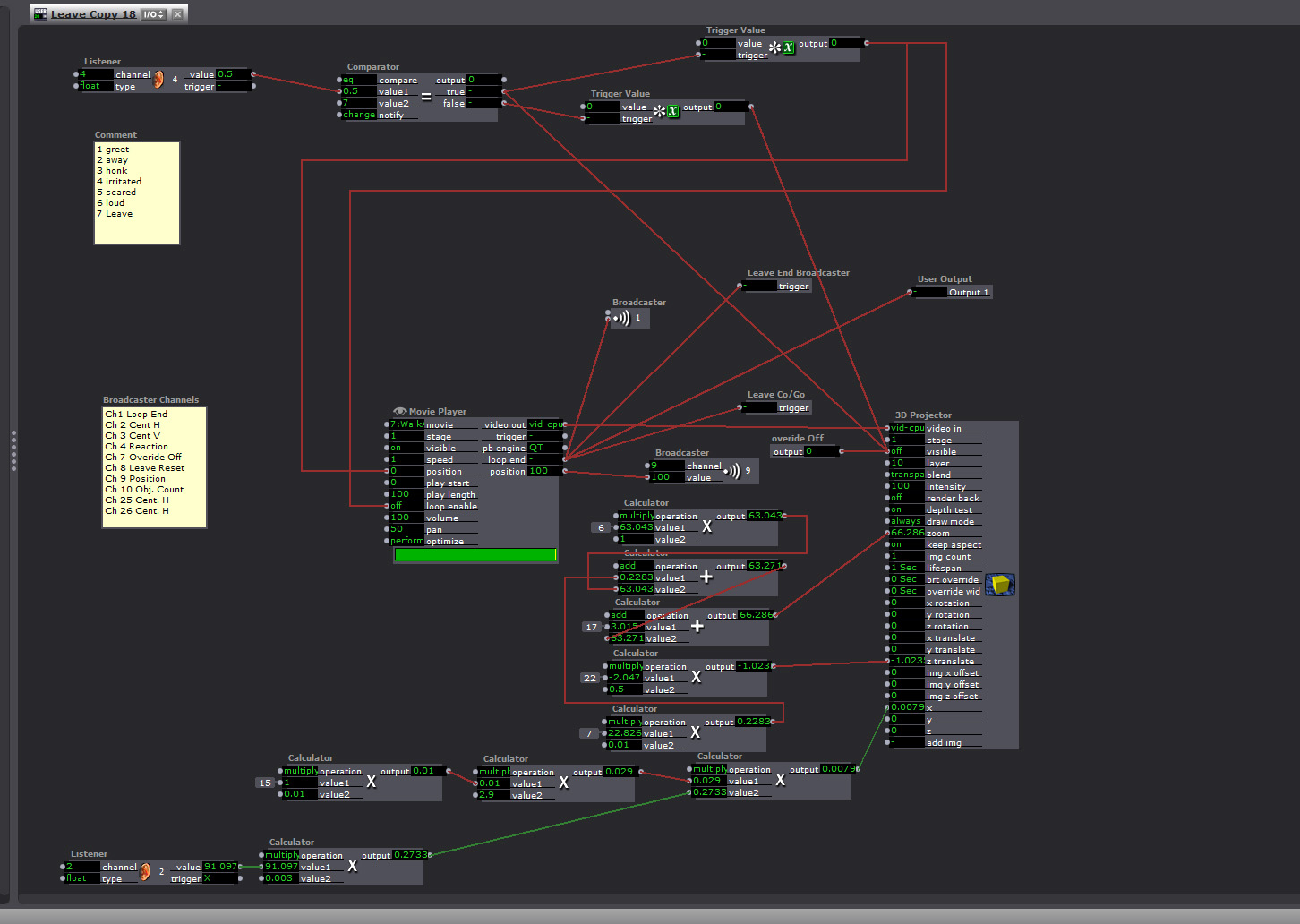
“Playback Controller”
The response is generated in the Emotion Matrix, and this keeps the responses from triggering at the same time
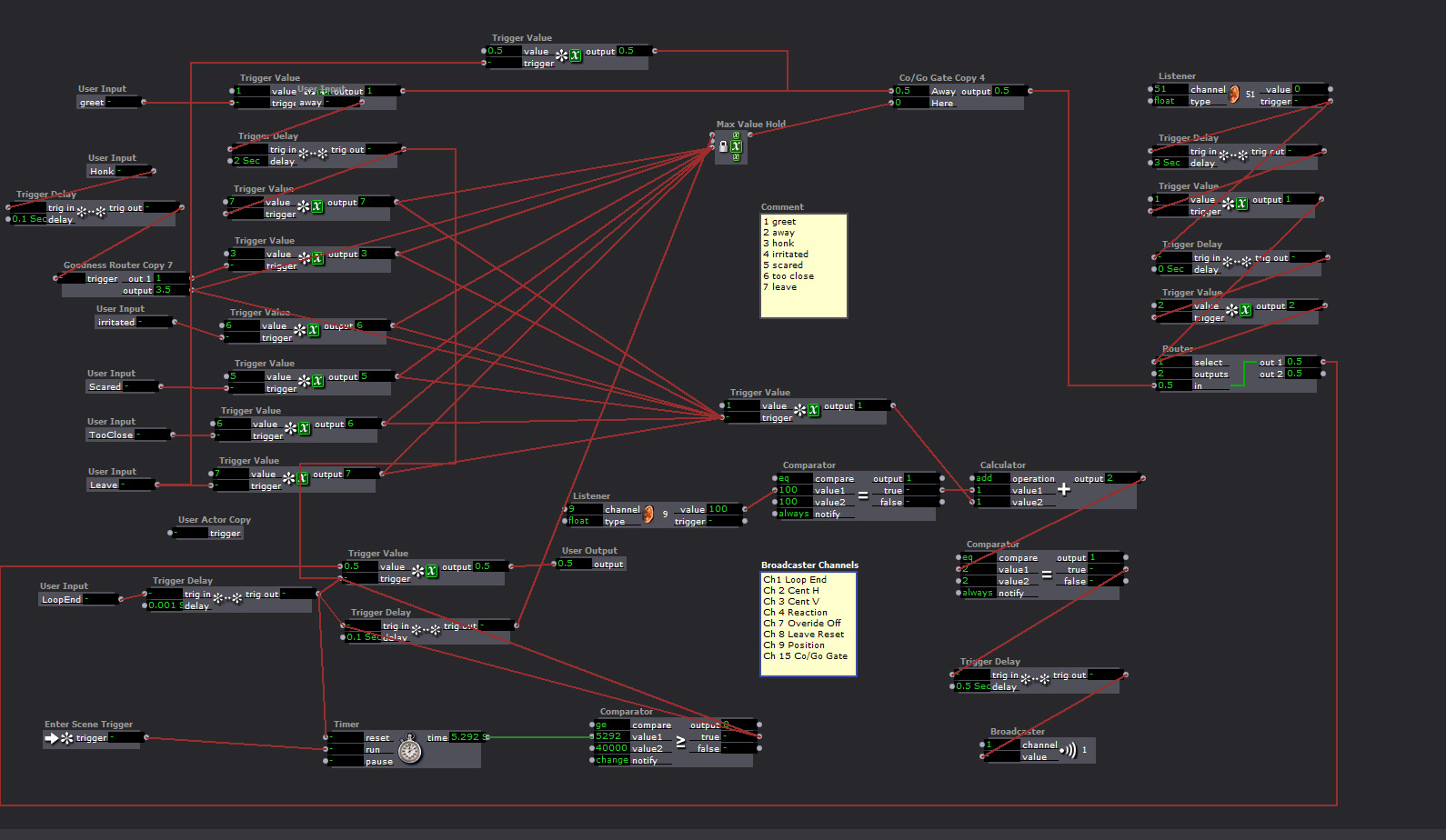
The “Emotion Matrix”
Too much fast motion, getting too close, being too loud, or too many people around would generate a response, and add negative points to the goose’s attatude. If the score got too high, he would leave. If you did not have any negative points and you said something at normal talking tone volume, the goose would give you a blessing. If you had been loud or done something to irritate him, he would just say “Hey”. The irritants would go down over time, but if you got too many in too short a time the goose would walk away.
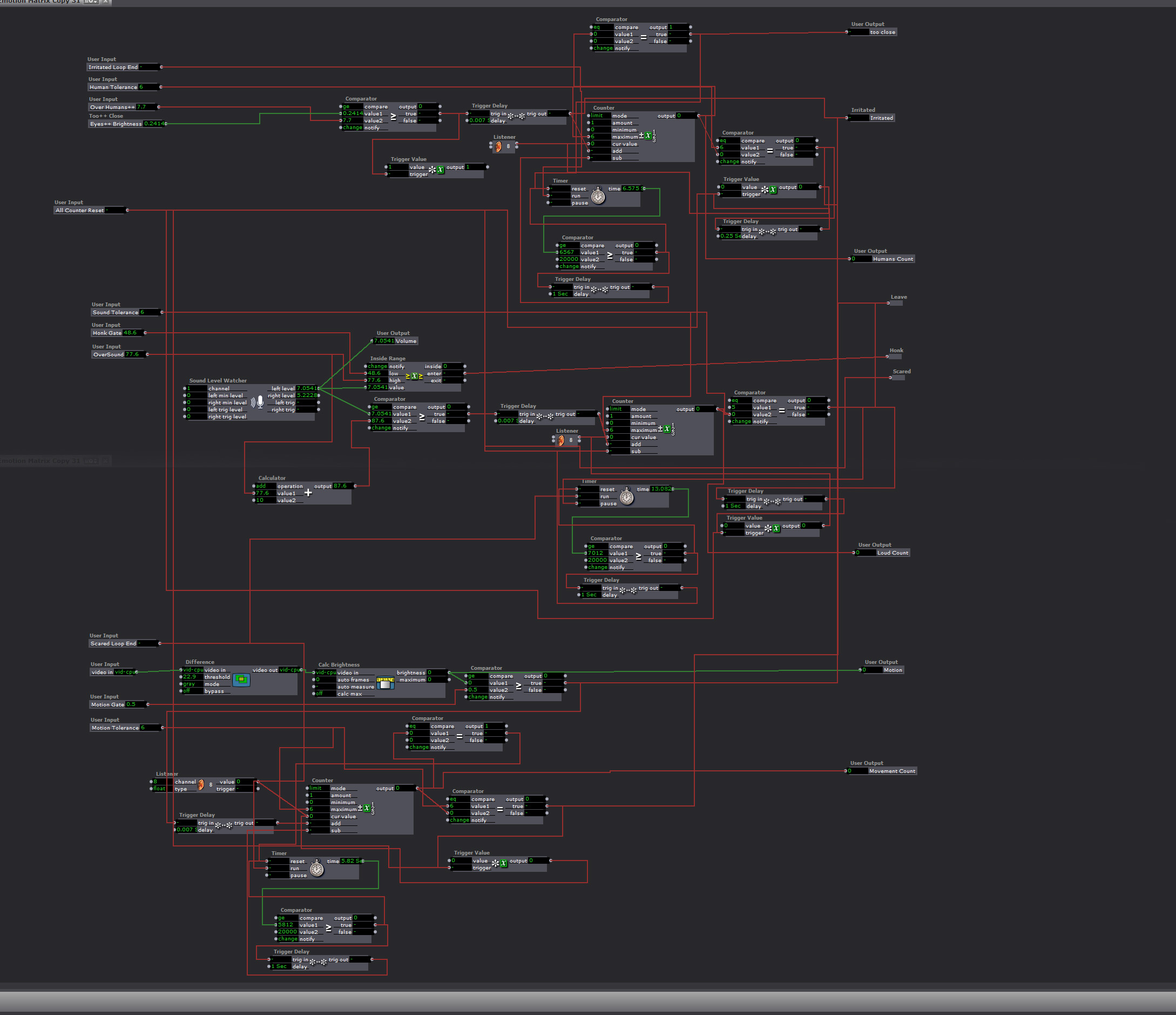
The “Goodness Elevator”
This took input from the negative response counter and routed the “Honk” response to a blessing if the count was 0 on all negative emotions.
What went wrong…
The background interlacing reduced the refresh rate to under 1 FPS at times. At such a slow rate several of the triggers that start the next response arrive at the same time. There were redundancies to keep them from all happening at once, and to keep a response from starting when one had been triggered but at 1 FPS they were all happening at once.
I had a broadcaster that was sending the player position that was used to ensure the players did not respond at the same time, and to trigger the next response when the last one was over. A “comparator” and a “router” kept the signals from starting while a player was playing, but if too many signals came at once, and the refresh rate was too low, there was no way to keep one response from starting while the other was playing.
I finally fixed it by eliminating the live feed, and the moving background. I tried just replacing the4 live feed with a photo, but interlacing it, and moving the background image was more than the computer could handle.
Final Project
Posted: December 17, 2015 Filed under: Final Project, Josh Poston Leave a comment »Well I had a huge final patch and because of the resource limitations of the MOLA finished the product on my computer. Which then crashed so goodbye to that patch. Here is something close to what my final patch was. Enjoy.
This is the opening scene. It is the welcome message and instructions.
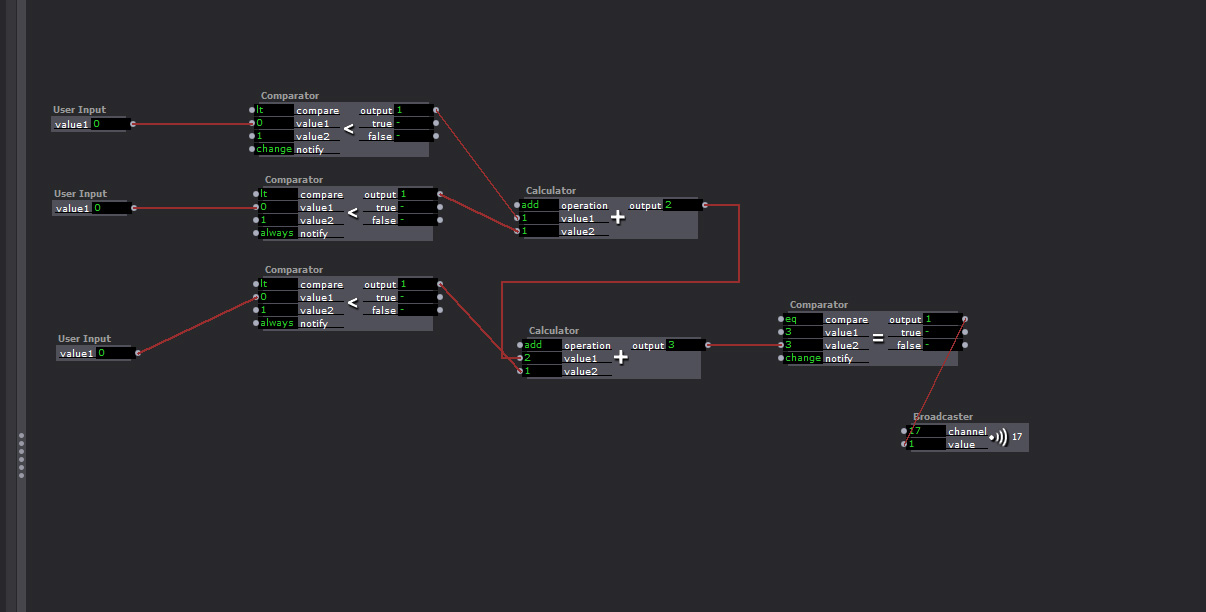
This is the Snowboard scene 2. It is triggered by timer at the end of the welcome screen. First picture is the kinect input and the movie/ mask making. Also the proximity detector and exploder actor.
This image is of the obstacle generation and the detection system.
This is the static background image and the kinect inputs/ double proximity detector for dodgeball. 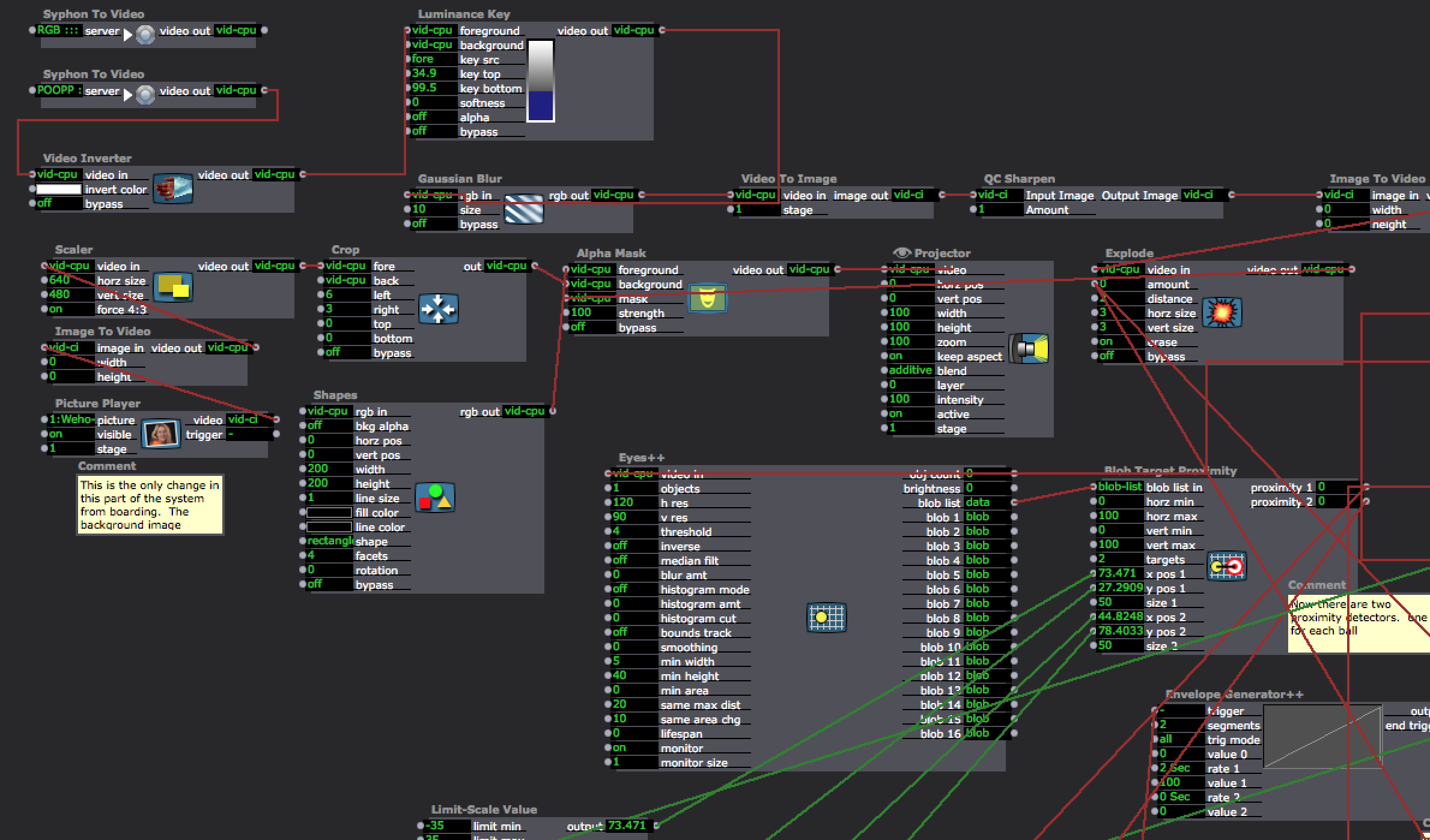
This image is of one of the dodgeball actors. the other is exactly the same just with slightly different shape color.
This image shows the 4 inputs necessary to track the proximity of the dodgeballs (obstacles) to the avatar when both x and y is a variable of object movement. Notice that because there are two balls there are two gates and triggers.
There is Only Software Response
Posted: December 17, 2015 Filed under: Josh Poston, Reading Responses 1 Comment »I understand what is being said by Manovich. However I refuse to accept this answer. I think that a more accurate statement is that in this day and age only software and hardware in tandem can achieve success. Software relies upon the physical realities of a machine. This is why new hardware is constantly being developed. For example attempt to run the current iteration of itunes on a generation 1 ipod. Very little success will be had. However hardware is only successfully implemented in tandem with software. A kinect while sensing images cant communicate that to anyone without software to analyze and synthesize the data.
“Trailhead” Final project update
Posted: December 15, 2015 Filed under: Uncategorized Leave a comment »Reflection

Photo by Alex Oliszewski
I am very pleased with how my final iteration of this project went. Not all of the triggers worked perfectly (the same scene was always finicky, which could have called for some final tweaking), but the interactivity I was looking for occurred.
Please refer to my video documentation of the participants experience and experiments with the light projections:
When I had the opportunity to discuss the participants interactions here is the feedback I received as well as my observations.
- One participant suggested I play with the velocity as a reactive element, using slow as well as fast as options. I explained that this actual was a step in the creation process but I preferred the allure of the constant light. I would like to in the future use the velocity in a different way because I agree it would add a lot of interest to the experience.
- When I asked them to “paint” the light with their hands, they actually rubbed their hands on the ground not in the air like patch necessitated. I realized after the first cycle of participants that using wording more akin to “conducting” would give them the depth information they would need to interact.
- I found that their impetus after interacting for a while was to use try and use their feet to manipulate the light because the light was projected onto the floor. Giving them information about their vertical depth being a factor of body recognition would have helped them. On the contrary though, I did enjoy watching the discovery process unfold on its own as their legs got higher off the ground and the projection began to appear.
- Another participant, when asked how they decided to move after seeing the experiential media said it was in a way of curiosity. They wanted to ask to test the limits of the interaction.
- The most exciting feedback for me was when a final participant expressed their self-proclaimed ‘non-dancer’ status but said my patch encouraged them to move in new ways. Non movers found themselves moving because of the interest the projection generated. So cool!
I wanted to give the participants a little bit of information about the patch but not too much as to spoon feed it to them. The written prompts worked well, but as stated above, the “paint” wording while poetic was not effective.
Kinect to Isadora
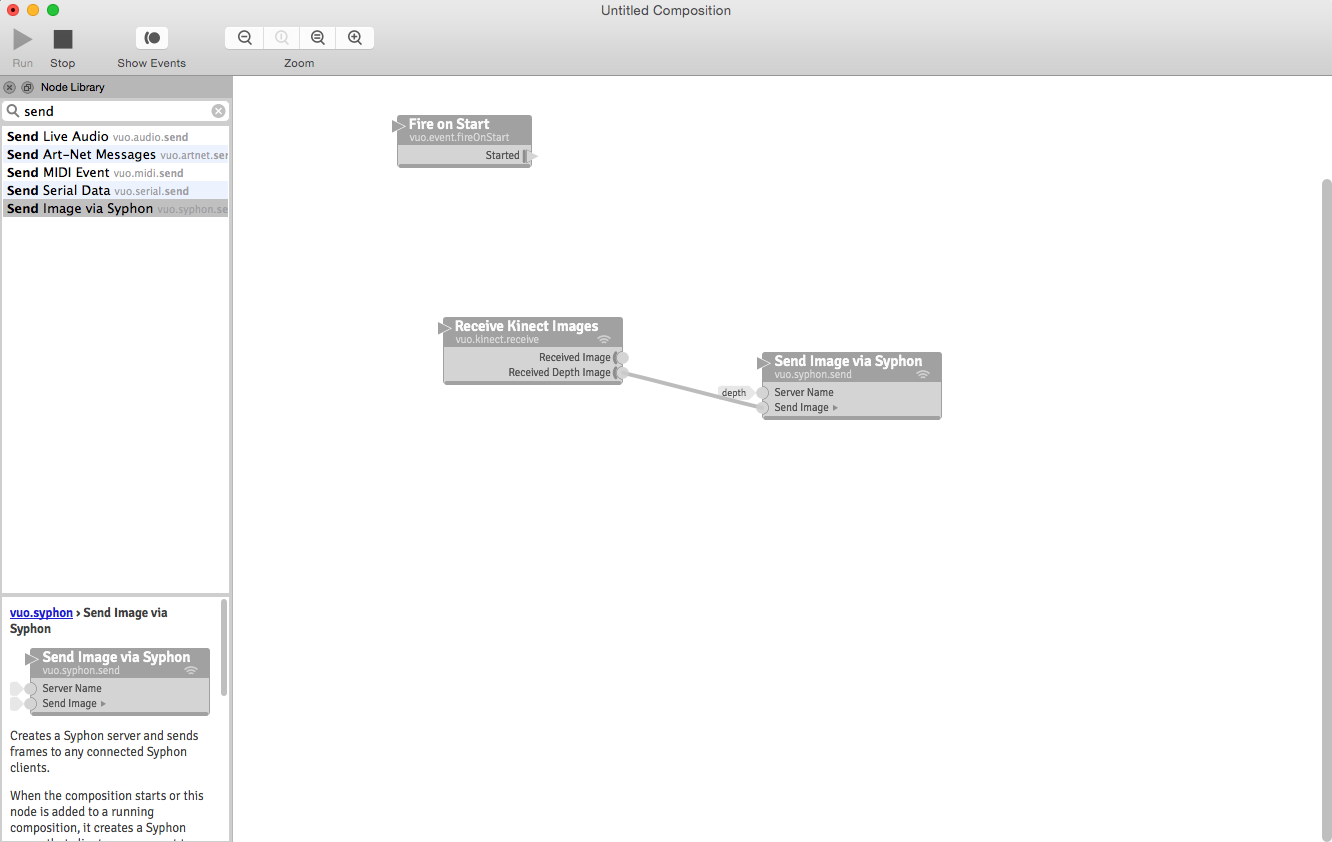
VUO Connection- Feed Kinect depth data into Isadora
Isadora Patch Details
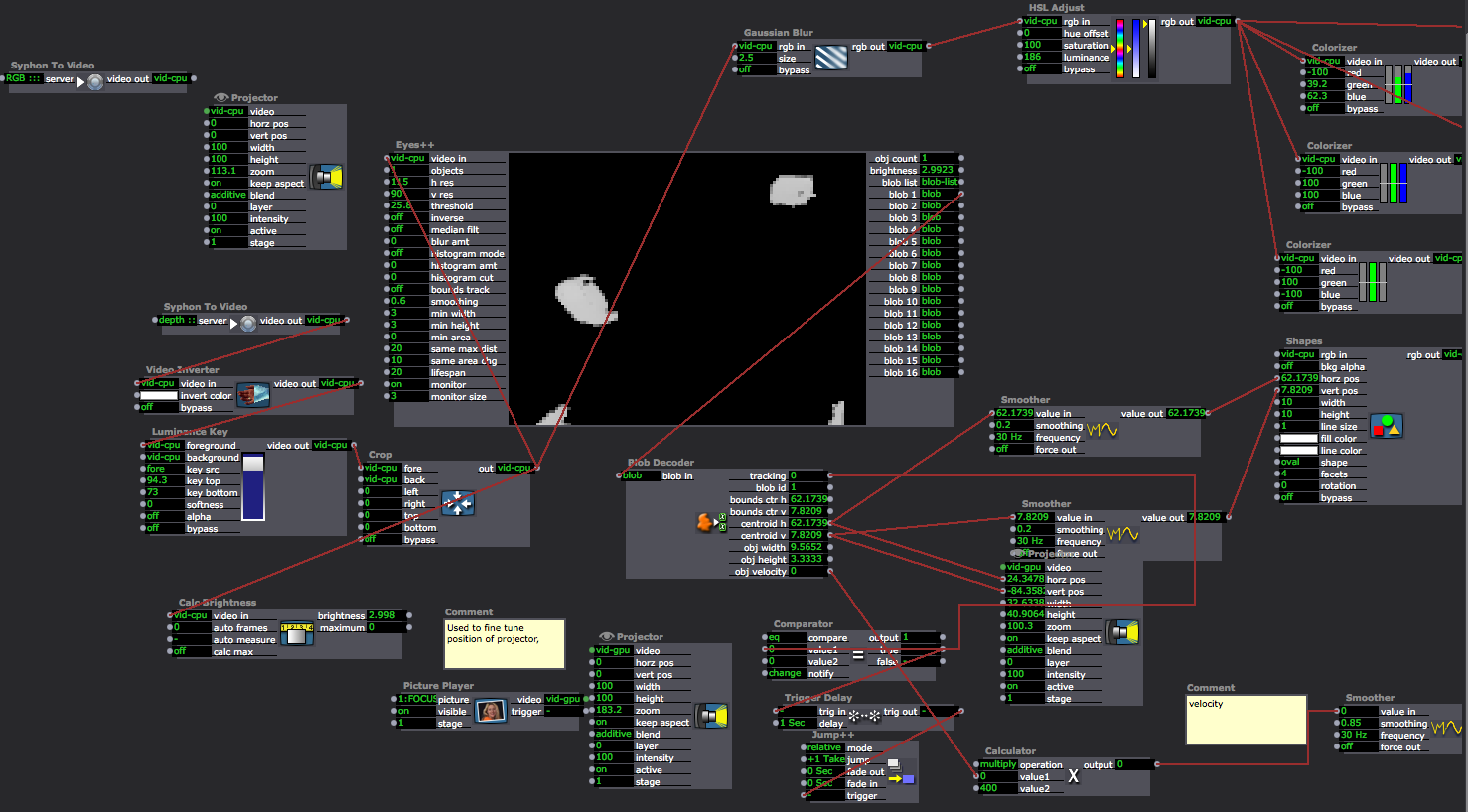
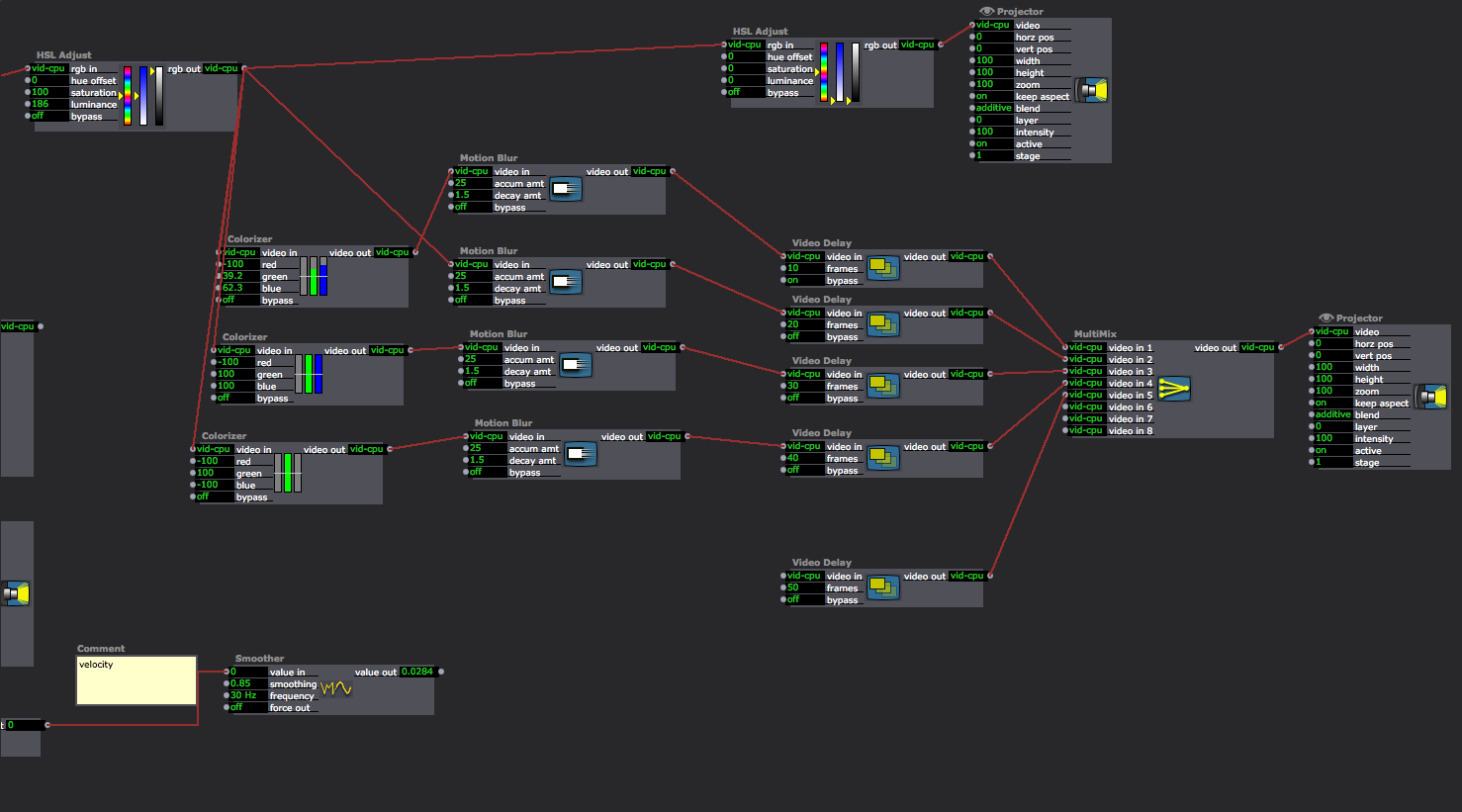
Scene Names/Organization
![]()
“Come to me,” “Take a knee: Paint the light with your hands,” and “A little faster now” were all text prompts that would trigger when a person exited the space to give them instructions for their next interaction. The different “mains” was the actual trailing projection itself, separated into different colors. Finally, the “Fin, back to the top!” screen was simply there for a few seconds to reveal they had reached the end and the patch would loop all over again momentarily. This could potentially cause an infinite loop of interactivity, allowing participants to observe others and find new ways of spreading, interacting, hiding and manipulating the projected light.
I am excited to take this patch, intelligence, feedback forward with me into my dance studies. I am going to integrate a variant of this project immediately into my performance in the Department of Dance’s Winter Concert in February of 2016, of which I have a piece of choreography and soon an experiential projection, in.

Photo by Alex Oliszewski
Fin!
Final Project
Posted: December 13, 2015 Filed under: Pressure Project 3, Sarah Lawler, Uncategorized 1 Comment »Below is a zip file of my final project along with some screen shots of the patch and images embedded into the index of the patch.
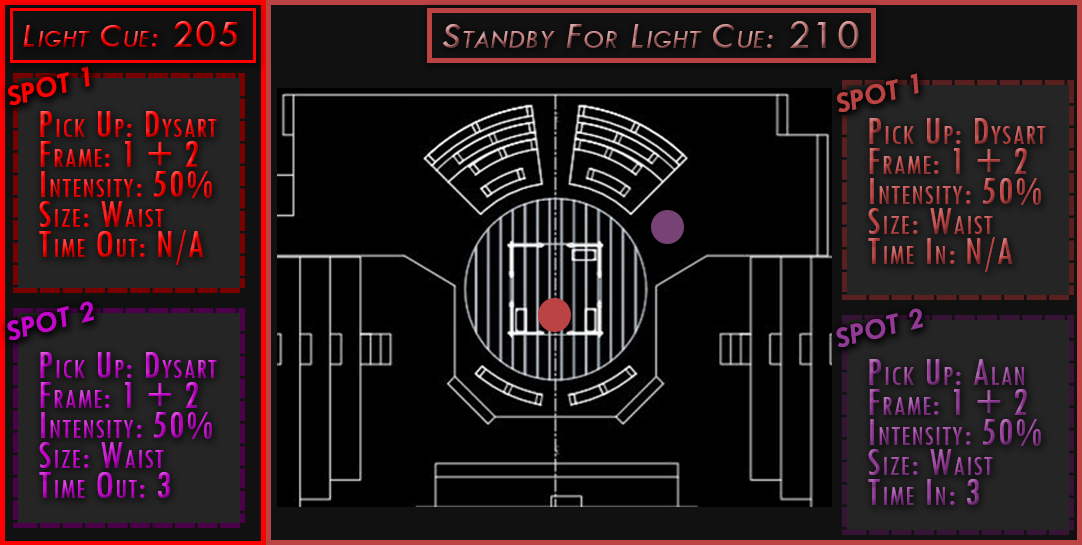
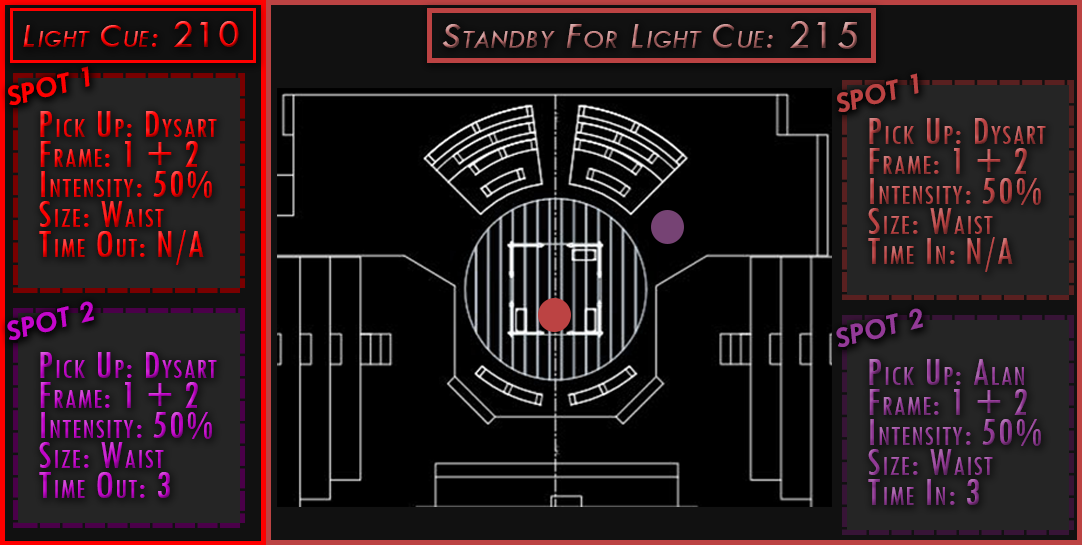
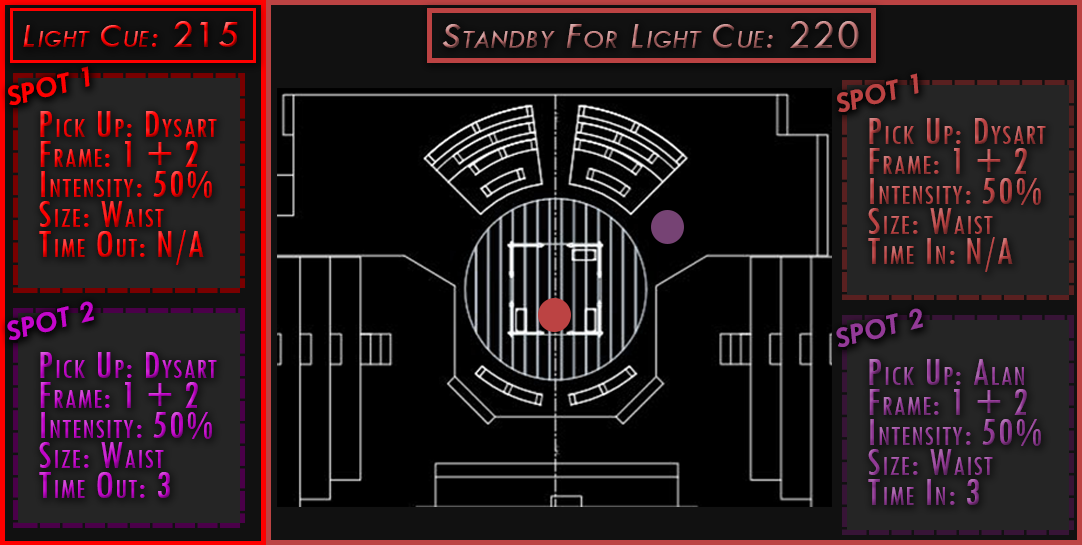
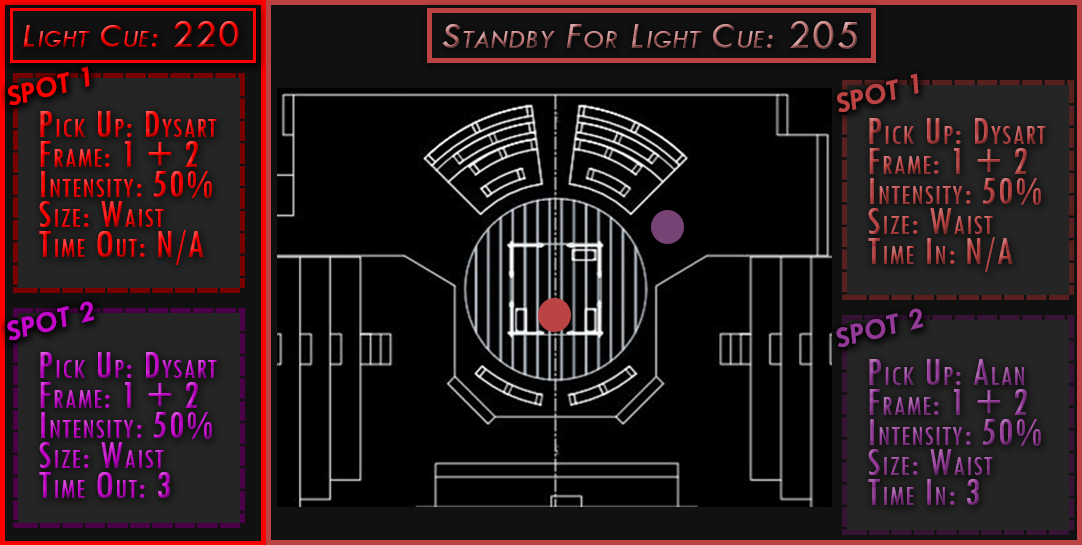
The overall design of this project was based off of being an emergency spot light operator. There was no physical way to read cues on a sheet of paper while operating a spotlight. This read only system is a prototype. The images are pushed to a tablet sitting in front of the spot light operator based off the cues in the light board. The spot light operator can then determine what cue they need to be in standby for hands free.
How To Make An Imaginary Friend
Posted: December 13, 2015 Filed under: Anna Brown Massey, Final Project 1 Comment »An audience of six walk into a room. They crowd the door. Observing their attachment to remaining where they’ve arrived, I am concerned the lights are set too dark, indicating they should remain where they are, safe by a wall, when my project will soon require the audience to station themselves within the Kinect sensor zone at the room’s center. I lift the lights in the space, both on them and into the Motion Lab. Alex introduces the concepts behind the course, and welcomes me to introduce myself and my project.
In this prototype, I am interested in extracting my live self from the system so that I may see what interaction develops without verbal directives. I say as much, which means I say little, but worried they are still stuck by the entrance (that happens to host a table of donuts), I say something to the effect of “Come into the space. Get into the living room, and escape the party you think is happening by the kitchen.” Alex says a few more words about self-running systems–perhaps he is concerned I have left them too undirected–and I return to station myself behind the console. Our six audience members, now transformed into participants, walk into the space.

Participants approach the Action Zone.
I designed How to make an imaginary friend as a schema to compel audience members, now rendered participants, to respond interactively through touching each other. Having achieved a learned response to the system and gathered themselves in a large single group because of the cumulative audio and visual rewards, the system would independently switch over to a live video feed as output, and their own audio dynamics as input, inspiring them to experiment with dynamic sound.
System as Descriptive Flow Chart
Front projection and Kinect are on, microphone and video camera are set on a podium, and Anna triggers Isadora to start scene.
> Audience enters MOLA
“Enter the action zone” is projected on the upstage giant scrim
> Intrigued and reading a command, they walk through the space until “Enter the action zone” disappears, indicating they have entered.
Further indication of being where there is opportunity for an event is the appearance of each individual’s outline of their body projected on the blank scrim. Within the contours of their projected self appears that slice of a movie, unmasked within their body’s appearance on the scrim when they are standing within the action zone.
> Inspired to see more of the movie, they realize that if they touch or overlap their bodies in space, they will be able to see more of the movie.

In attempts at overlapping, they touch, and Isadora reads a defined bigger blob, and sets off a sound.
> Intrigued by this sound trigger, more people overlap or touch simultaneously, triggering more sounds.
> They sense that as the group grows, different sounds will come out, and they continue to connect more.
Reaching the greatest size possible, the screen is suddenly triggered away from the projected appearance, and instead projects a live video feed.
They exclaim audibly, and notice that the live feed video projection changes.
> The louder they are, the more it zooms into a projection of themselves.
They come to a natural ending of seeing the next point of attention, and I respond to any questions.
Analysis of Prototype Experiment 12/11/15
As I worked over the last number of weeks I recognized that shaping an experiential media system renders the designer a Director of Audience. I newly acknowledged once the participants were in the MOLA and responding to my design, I had become a Catalyzer of Decisions. And I had a social agenda.
There is something about the simple phrase “I want people to touch each other nicely” that seems correct, but also sounds reductive–and creepily problematic. I sought to trigger people to move and even touch strangers without verbal or text direction. My system worked in this capacity. I achieved my main goal, but the cumulative triggers and experiences were limited by an all-MOLA sound system failure after the first few minutes. The triggered output of sound-as-reward-for-touch worked only for the first few minutes, and then the participants were left with a what-next sensibility sans sound. Without a working sound system, the only feedback was the further discovery of unmasking chunks of the film.

Participant experiments with body placement to determine triggers.
Because of the absence of the availability of my further triggers, I got up and joined them. We talked as we moved, and that itself interested me–they wanted to continue to experiment with their avatars on screen despite a lack of audio trigger and an likely a growing sense that they may have run out of triggers. Should the masked movie been more engaging (this one was of a looped train rounding a station), they might have been further engaged even without the audio triggers. In developing this work, I had considered designing a system in which there was no audio output, but instead the movement of the participants would trigger changes in the film–to fast forward, stop, alter the image. This might be a later project, and would be based in the Kinect patch and dimension data. Further questions arise: What does a human body do in response to their projected self? What is the poetic nature of space? How does the nature of looking at a screen affect the experience and action of touch?
Plans for Following Iteration
- “Action zone” text: need to dial down sensitivity so that it appears only when all objects are outside of the Kinect sensor area.
- Not have the sound system for the MOLA fail, or if this happens again, pause the action, set up a stopgap of a set of portable speakers to attach to the laptop running Isadora.
- Have a group of people with which to experiment to more closely set the dimensions of the “objects” so that the data of their touch sets off a more precisely linked sound.
- Imagine a different movie and related sound score.
- Consider an opening/continuous soundtrack “background” as scene-setting material.
- Consider the integrative relationship between the two “scenes”: create a satisfying narrative relating the projected film/touch experience to the shift to the audio input into projected screen.
- Relocate the podium with microphone and videocamera to the center front of the action zone.
- Examine why the larger dimension of the group did not trigger the trigger of the user actor to switch to the microphone input and live video feed output.
- Consider: what was the impetus relationship between the audio output and the projected images? Did participants touch and overlap out of desire to see their bodies unmask the film, or were they relating to the sound trigger that followed their movement? Should these two triggers be isolated, or integrated in a greater narrative?
Video available here: https://vimeo.com/abmassey/imaginaryfriend
Password: imaginary
All photos above by Alex Oliszewski.
Software Screen Shots
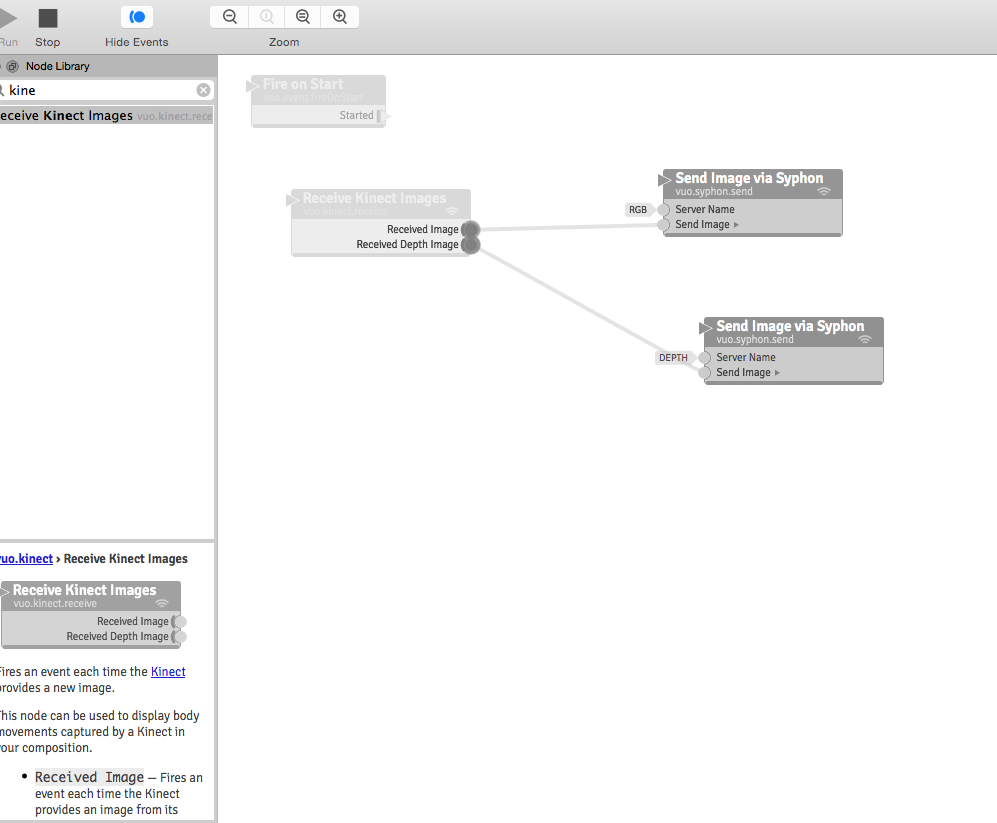
Vuo (Demo) Software connecting the Kinect through Syphon so that Isadora may intake the Kinect data through a Syphon actor:
Partial shot of the Isadora patch:
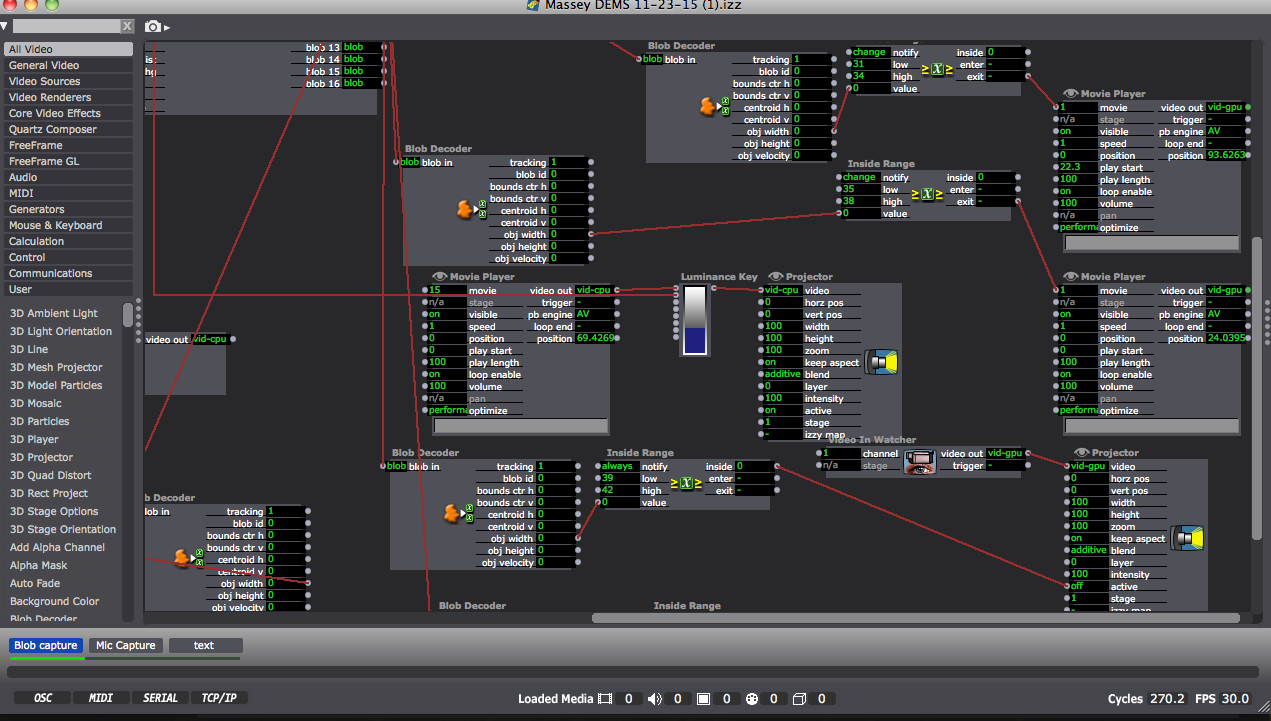
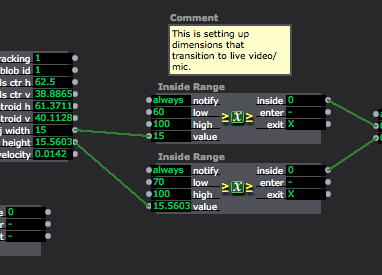
Close up of “blob” data or object dimensions coming through on the left, mediated through the Inside range actors as a way of triggering the Audio scene only when the blobs (participants) reach a certain size by joining their bodies:
Final Project Showing
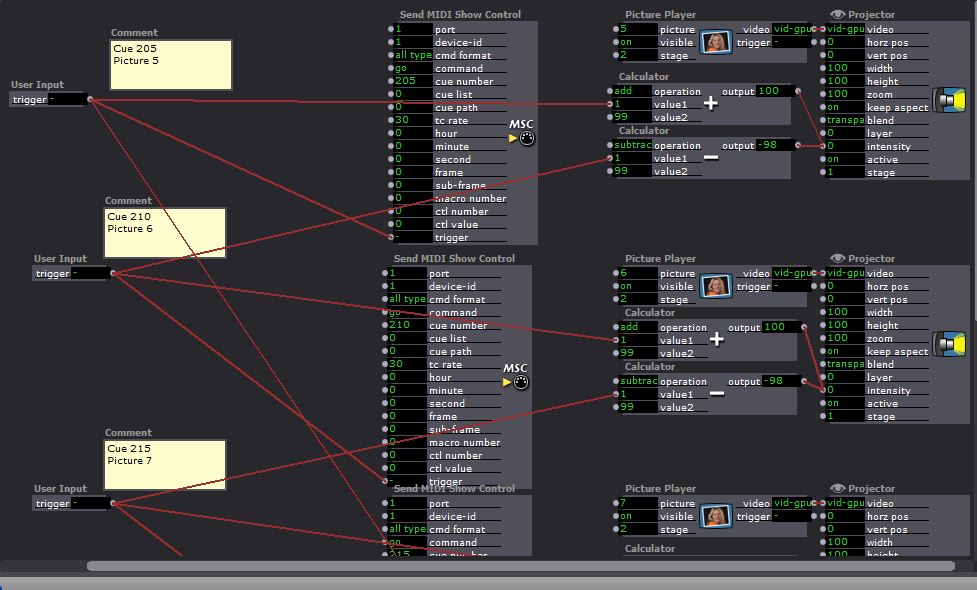
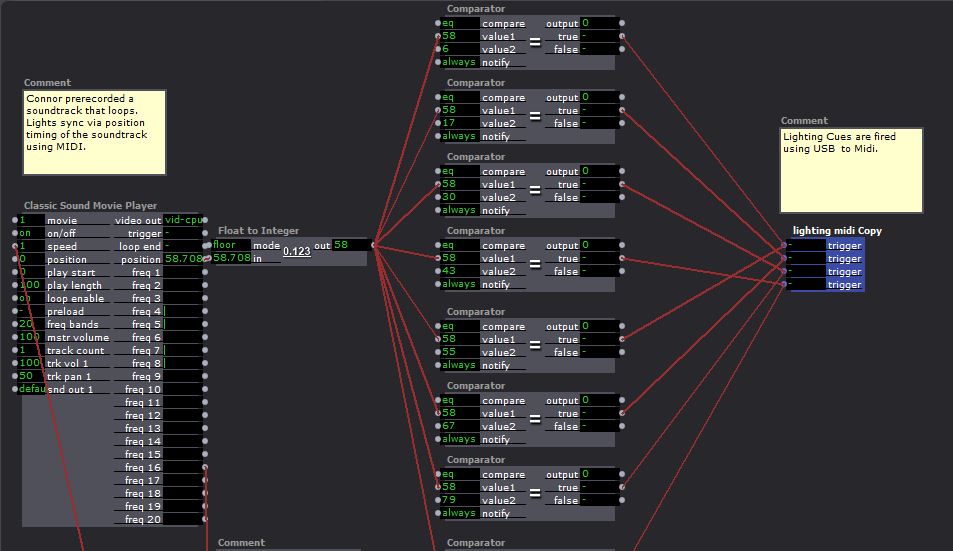
Posted: December 12, 2015 Filed under: Connor Wescoat, Final Project Leave a comment »I have done a lot of final presentations during the course of my college career but never one quite like this. Although the theme of event was “soundboard mishaps”, I was still relatively satisfied with the way everything turned out. The big take away that I got from my presentation was that some people are intimidated when put on the spot. I truly believe that anyone of the audience could of come up with something creative if they got 10 minutes to themselves with my showing to just play around with it. While I did not for see the result, I was satisfied that one of the 6 members actually got into the project and I could visually see that he was having fun. In conclusion, I enjoyed the event and the class. I met a lot of great people and I look forward to seeing/working with anyone of my classmates in the future. Thank you for a great class experience! Attached are screen shots of the patch. The top is the high/mid/low frequency analysis while the bottom is the prerecorded guitar piece that is synced up to the lights and background.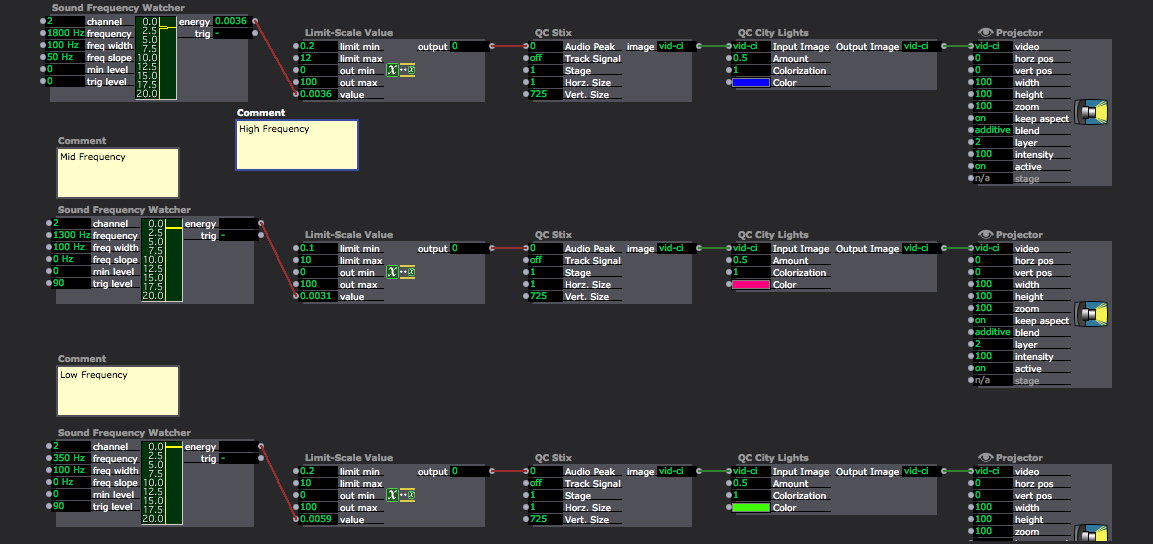
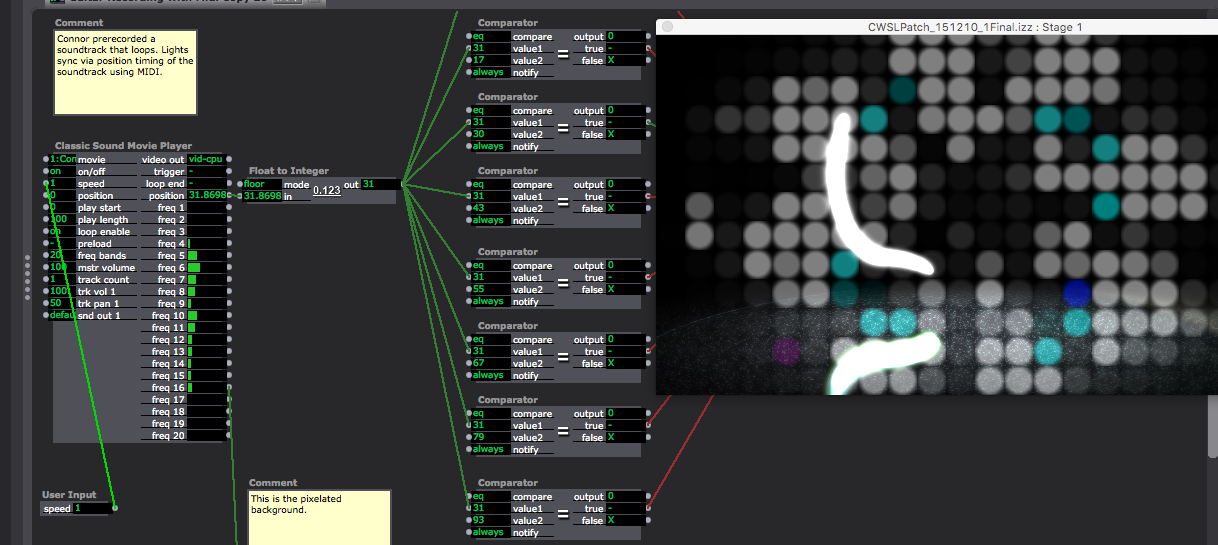
Documentation Pictures From Alex
Posted: December 12, 2015 Filed under: Uncategorized Leave a comment »Hi all,
You can find copies of the pictures I took from the public showing here:
https://osu.box.com/s/ff86n30b1rh9716kpfkf6lpvdkl821ks
Please let me know if you have any problems accessing them.
-Alex
Final Project Patch Update
Posted: December 2, 2015 Filed under: Alexandra Stilianos, Final Project Leave a comment »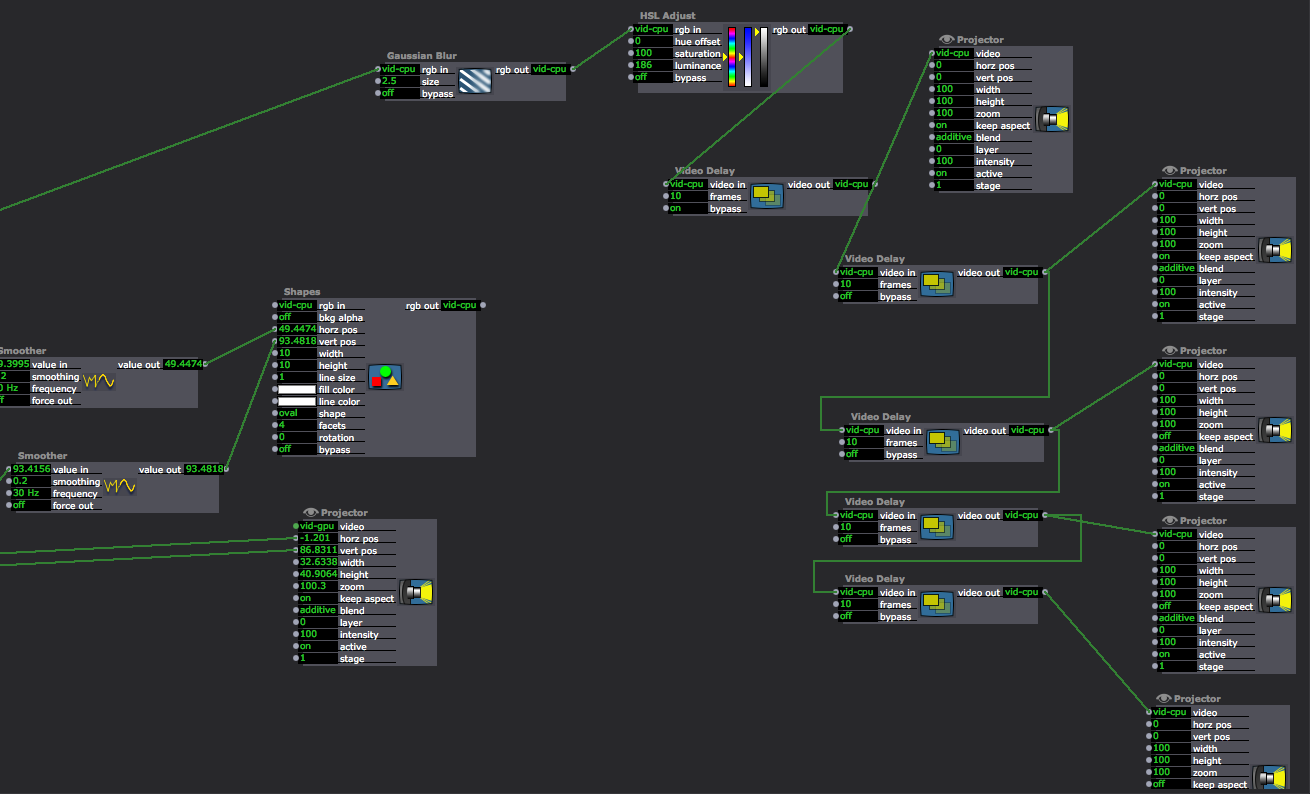
Last week I attempted to use the video delays to create a shadow trail of the projected light in space and connect them to one projector. I plugged all the video delay actors into each other and then one projector which caused them to only be associated to one image. Then, when separating the video delays and giving them their own projectors and giving them their own delay times, the effect was successful.
Today (Wednesday) in class, we adjusted the Kinect and the Projector to be aiming straight towards the ground so the reflection caused by the floor from the infrared lights in the Kinect would no longer be a distraction.
I also raised the depth that the Kinect can read from a persons shins and up so when you are below that area the projection no longer appears. For example, a dancers can take a few steps and then roll to the ground and end in a ball and the projection will follow and slowly disappear, even with the dancer still within range of the kinect/projector. They are just below the readable area.