How To Make An Imaginary Friend
Posted: December 13, 2015 Filed under: Anna Brown Massey, Final Project 1 Comment »An audience of six walk into a room. They crowd the door. Observing their attachment to remaining where they’ve arrived, I am concerned the lights are set too dark, indicating they should remain where they are, safe by a wall, when my project will soon require the audience to station themselves within the Kinect sensor zone at the room’s center. I lift the lights in the space, both on them and into the Motion Lab. Alex introduces the concepts behind the course, and welcomes me to introduce myself and my project.
In this prototype, I am interested in extracting my live self from the system so that I may see what interaction develops without verbal directives. I say as much, which means I say little, but worried they are still stuck by the entrance (that happens to host a table of donuts), I say something to the effect of “Come into the space. Get into the living room, and escape the party you think is happening by the kitchen.” Alex says a few more words about self-running systems–perhaps he is concerned I have left them too undirected–and I return to station myself behind the console. Our six audience members, now transformed into participants, walk into the space.

Participants approach the Action Zone.
I designed How to make an imaginary friend as a schema to compel audience members, now rendered participants, to respond interactively through touching each other. Having achieved a learned response to the system and gathered themselves in a large single group because of the cumulative audio and visual rewards, the system would independently switch over to a live video feed as output, and their own audio dynamics as input, inspiring them to experiment with dynamic sound.
System as Descriptive Flow Chart
Front projection and Kinect are on, microphone and video camera are set on a podium, and Anna triggers Isadora to start scene.
> Audience enters MOLA
“Enter the action zone” is projected on the upstage giant scrim
> Intrigued and reading a command, they walk through the space until “Enter the action zone” disappears, indicating they have entered.
Further indication of being where there is opportunity for an event is the appearance of each individual’s outline of their body projected on the blank scrim. Within the contours of their projected self appears that slice of a movie, unmasked within their body’s appearance on the scrim when they are standing within the action zone.
> Inspired to see more of the movie, they realize that if they touch or overlap their bodies in space, they will be able to see more of the movie.

In attempts at overlapping, they touch, and Isadora reads a defined bigger blob, and sets off a sound.
> Intrigued by this sound trigger, more people overlap or touch simultaneously, triggering more sounds.
> They sense that as the group grows, different sounds will come out, and they continue to connect more.
Reaching the greatest size possible, the screen is suddenly triggered away from the projected appearance, and instead projects a live video feed.
They exclaim audibly, and notice that the live feed video projection changes.
> The louder they are, the more it zooms into a projection of themselves.
They come to a natural ending of seeing the next point of attention, and I respond to any questions.
Analysis of Prototype Experiment 12/11/15
As I worked over the last number of weeks I recognized that shaping an experiential media system renders the designer a Director of Audience. I newly acknowledged once the participants were in the MOLA and responding to my design, I had become a Catalyzer of Decisions. And I had a social agenda.
There is something about the simple phrase “I want people to touch each other nicely” that seems correct, but also sounds reductive–and creepily problematic. I sought to trigger people to move and even touch strangers without verbal or text direction. My system worked in this capacity. I achieved my main goal, but the cumulative triggers and experiences were limited by an all-MOLA sound system failure after the first few minutes. The triggered output of sound-as-reward-for-touch worked only for the first few minutes, and then the participants were left with a what-next sensibility sans sound. Without a working sound system, the only feedback was the further discovery of unmasking chunks of the film.

Participant experiments with body placement to determine triggers.
Because of the absence of the availability of my further triggers, I got up and joined them. We talked as we moved, and that itself interested me–they wanted to continue to experiment with their avatars on screen despite a lack of audio trigger and an likely a growing sense that they may have run out of triggers. Should the masked movie been more engaging (this one was of a looped train rounding a station), they might have been further engaged even without the audio triggers. In developing this work, I had considered designing a system in which there was no audio output, but instead the movement of the participants would trigger changes in the film–to fast forward, stop, alter the image. This might be a later project, and would be based in the Kinect patch and dimension data. Further questions arise: What does a human body do in response to their projected self? What is the poetic nature of space? How does the nature of looking at a screen affect the experience and action of touch?
Plans for Following Iteration
- “Action zone” text: need to dial down sensitivity so that it appears only when all objects are outside of the Kinect sensor area.
- Not have the sound system for the MOLA fail, or if this happens again, pause the action, set up a stopgap of a set of portable speakers to attach to the laptop running Isadora.
- Have a group of people with which to experiment to more closely set the dimensions of the “objects” so that the data of their touch sets off a more precisely linked sound.
- Imagine a different movie and related sound score.
- Consider an opening/continuous soundtrack “background” as scene-setting material.
- Consider the integrative relationship between the two “scenes”: create a satisfying narrative relating the projected film/touch experience to the shift to the audio input into projected screen.
- Relocate the podium with microphone and videocamera to the center front of the action zone.
- Examine why the larger dimension of the group did not trigger the trigger of the user actor to switch to the microphone input and live video feed output.
- Consider: what was the impetus relationship between the audio output and the projected images? Did participants touch and overlap out of desire to see their bodies unmask the film, or were they relating to the sound trigger that followed their movement? Should these two triggers be isolated, or integrated in a greater narrative?
Video available here: https://vimeo.com/abmassey/imaginaryfriend
Password: imaginary
All photos above by Alex Oliszewski.
Software Screen Shots
Vuo (Demo) Software connecting the Kinect through Syphon so that Isadora may intake the Kinect data through a Syphon actor:
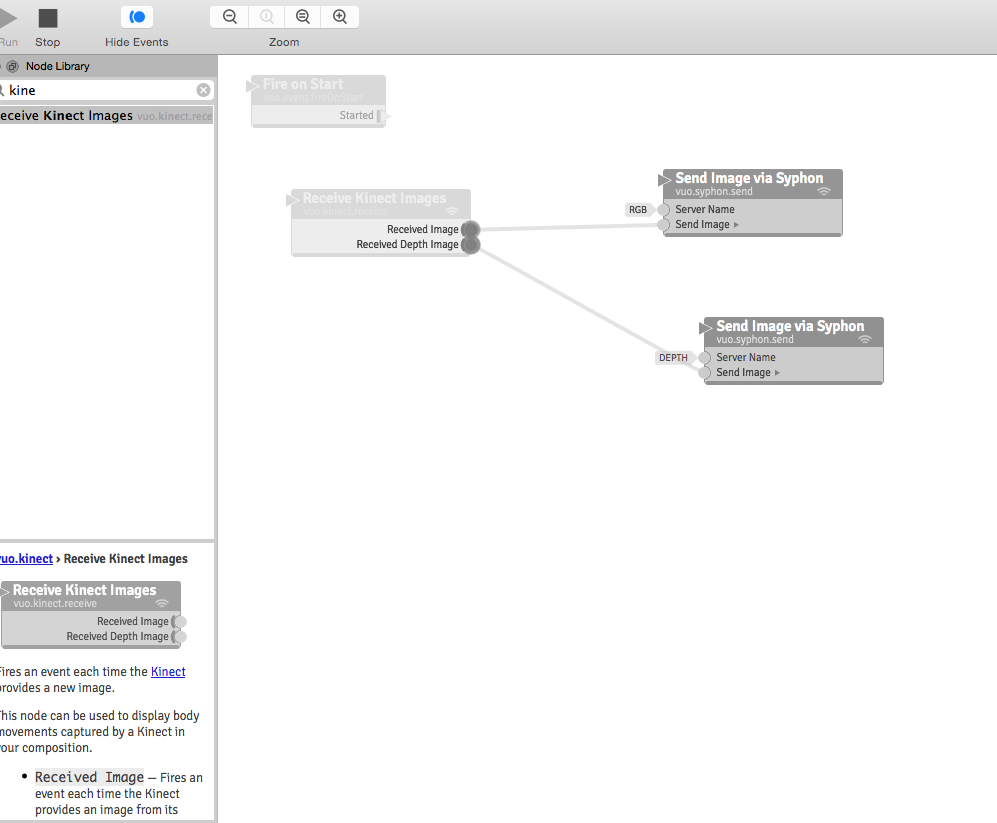
Partial shot of the Isadora patch:
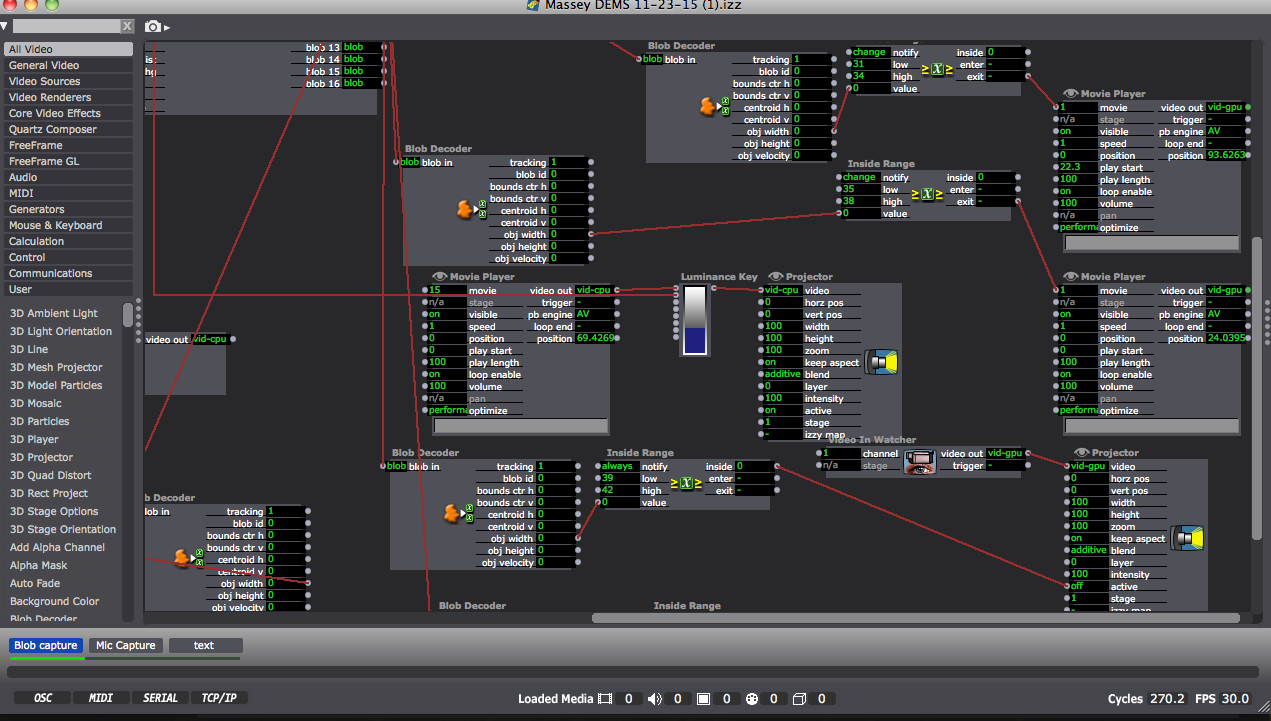
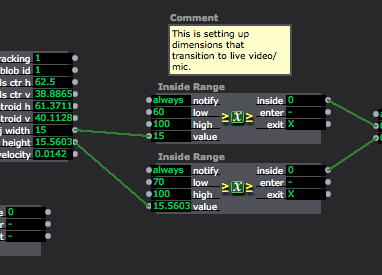
Close up of “blob” data or object dimensions coming through on the left, mediated through the Inside range actors as a way of triggering the Audio scene only when the blobs (participants) reach a certain size by joining their bodies:
One Comment on “How To Make An Imaginary Friend”
Leave a Reply
You must be logged in to post a comment.
I appreciate your organization and how thorough you are with your posts, Anna. You rock!