PP3 – Aut ’17
Posted: October 10, 2017 Filed under: Uncategorized Leave a comment »
Pen & Paper + (LEVEL 3 Pressure Project)
Context:
According to wikipedia, examples of Pen & Paper Games include ” Tic-tac-toe, Sprouts, and Dots and Boxes. Other games include: Hangman, Connect 5, M.A.S.H., Boggle, Battleships, Paper Soccer, and MLine.”
Assignment:
Choose a known (at least to you) pen & paper game*.
Combine it with another game. The second game can be another pen and pencil game, a card game, a dice game, or a interactive projection.
You have no more than 5 hours to complete this project. (Not including research.)
*Please feel free to keep things simple. Yet, here are some more adventurous examples:
- http://zenseeker.net/BoardGames/PaperPenGames.htm ,
- http://www.thegamesjournal.com/articles/GameSystems4.shtml,
Basic Limitations:
- new game can have no more than 5 rules
- a novice player must be able to play without your verbal or gestural intervention. (provide an instruction sheet with the rules.)
Basic Level 3 Achievements :
- Fun to play
- Game is delightfully repayable
Legendary Achievements:
- includes a plot driven narrative
- includes an interactive projection
Pressure Project #2: Alligators in the Sewers!
Posted: October 8, 2017 Filed under: Uncategorized Leave a comment »This audio exploration is designed to evoke sensation through sound in a whimsical way. Working from the myth of the alligators who live in the New York City subway system, I sketched out a one-minute narrative encounter that would be recognizable (especially to a city-dweller), a little creepy, and just a bit funny.
- A regular day on a busy New York City street
- The clatter of a manhole cover being opened
- Climbing down into the dark sewer
- Walking slowly through the dark through running water (and who knows what else)
- A sound in the distance . . . a pause
- The roar of an alligator!
Assembling these sounds was simply a matter of scouring YouTube, but mixing them proved to be a bit more challenging. I layered each track in GarageBand, paying special attention to the transition from the busy world above and the dark, industrial swamp below. I also worked to differentiate the sound of stepping down a ladder from the sound of walking through the tunnel. An overlay of swamp and sewer sounds created the atmosphere belowground, and a random water drop built the tension. It was important to stop the footsteps immediately after you hear the soft roar of the alligator in the distance, pause, and then bring in the loudest sequence of alligators roaring I could find.
The minute-long requirement was tricky to work with because of the relationship between time and tension. I think the project succeeds in general, but an extra minute or two could really ratchet up the sensations of moving from safety, to curiosity, to trepidation, to terror. Take a listen for yourself! I recommend turning off all the lights and lying on the floor.
Pressure Project 2 – 2017
Posted: September 22, 2017 Filed under: Uncategorized Leave a comment »PP2 – Media and Narrative:
This Pressure Project was originally offered to me by my Professor, Aisling Kelliher:
Topic – narrative sound and music
Select a story of strong cultural significance. For example this can mean an epic story (e.g. The Odyssey), a fairytale (e.g. Red Riding Hood), an urban legend (e.g. The Kidney Heist) or a story that has particular cultural meaning to you (e.g. WWII for me, Cuchulainn for Kelliher).
Tell us that story using music and audio as the the primary media. You can use just audio or combine with images/movies if you like. You can use audio from your own personal collections, from online resources or created by you (the same with any accompanying visuals). You should aim to tell your story in under a minute.
You have 5 hours to work on this project.
Navy plans to use X-Box 360 Controllers to control (parts of) their submarines
Posted: September 18, 2017 Filed under: Uncategorized Leave a comment »http://gizmodo.com/why-the-navy-plans-to-use-12-year-old-xbox-360-controll-1818511278
Pressure Project #1: (Mostly) Bad News
Posted: September 16, 2017 Filed under: Pressure Project I, Uncategorized Leave a comment »Pressure Project #1
My concept for this first Pressure Project emerged from research I am currently engaged in concerning structures of representation. The tarot is an on-the-nose example of just such a structure, with its Derridean ordering of signs and signifiers.
I began by sketching out a few goals:
The experience must evoke a sense of mystery punctuated by a sense of relief through humor or the macabre.
The experience must be narrative in that the user can move through without external instructions.
The experience must provide an embodied experience consistent with a tarot reading.
I began by creating a scene that suggests the beginning of a tarot reading. I found images of tarot cards and built a “Card Spinner” user actor that I could call. Using wave generators, the rotating cards moved along the x and y axes, and the z axis was simulated by zooming the cards in and out.

Next I built the second scene that suggest the laying of specific cards on the table. Originally I planned that the cards displayed would be random, but due to the time required to create an individual scene for each card I opted to simply display the three same cards.
Finally, I worked to construct a scene for each card that signified the physical (well, virtual) card that the user chose. Here I deliberately moved away from the actual process of tarot in order to evoke a felt sensation in the user.

I wrote a short, rhyming fortune for each card:
The Queen of Swords Card – Happiness/Laughter
The Queen of Swords
with magic wards
doth cast a special spell:
“May all your moments
be filled with donuts
and honeyed milk, as well.”
The scene for The Queen of Swords card obviously needed to incorporate donuts, so I found a GLSL shader of animated donuts. It ran very slowly, and after looking at the code I determined that the way the sprinkles were animated was extremely inefficient, so I removed that function. Pharrell’s upbeat “Happy” worked perfectly as the soundtrack, and I carefully timed the fade in of the fortune using trigger delays.

Judgment Card – Shame
I judge you shamed
now bear the blame
for deeds so foul and rotten!
Whence comes the bell
you’ll rot in hell
forlorn and fast forgotten!
The Judgement card scene is fairly straightforward, consisting of a background video of fire, an audio track of bells tolling over ominous music, and a timed fade in of the fortune.

Wheel of Fortune – Macabre
With spiny spikes
a crown of thorns
doth lie atop your head.
Weep tears of grief
in sad motif
‘cuz now your dog is dead.
The Wheel of Fortune card scene was more complicated. At first I wanted upside-down puppies to randomly drop down from the top of the screen, collecting on the bottom and eventually filling the entire screen. I could not figure out how to do this without having a large number of Picture Player actors sitting out of site above the stage, which seemed inelegant, so I opted instead to simply have puppies drop down from the stop of the stage and off the bottom randomly. Is there a way to instantiate actors programmatically? It seems like there should be a way to do this.

Now that I had the basics of each scene working, I turned to the logics of the user interaction. I did this in two phases:
In phase one I used keyboard watchers to move from one scene to the next or go back to the beginning. The numbers 1, 2, and 3, were hooked up on the selector scene to choose a card. Using the keyboard as the main interface was a simple way to fine-tune the transitions between scenes, and to ensure that the overall logic of the game made sense.
The biggest challenge I ran into during this phase was in the Wheel of Fortune scene. I created a Puppy Dropper user actor that was activated by pressing the “d” key. When activated, a puppy would drop from the top of the screen at a random horizontal point. However, I ran into a few problems:
- I had to use a couple of calculators between the envelope generator and the projector in order to get the vertical position scaling correct such that the puppy would fall from the top to the bottom
- Because the sound the puppy made when falling was a movie, I had to use a comparator to reset the movie after each puppy drop. My solution for this is convoluted, and I now see that using the “loop end” trigger on the movie player would have been more efficient.
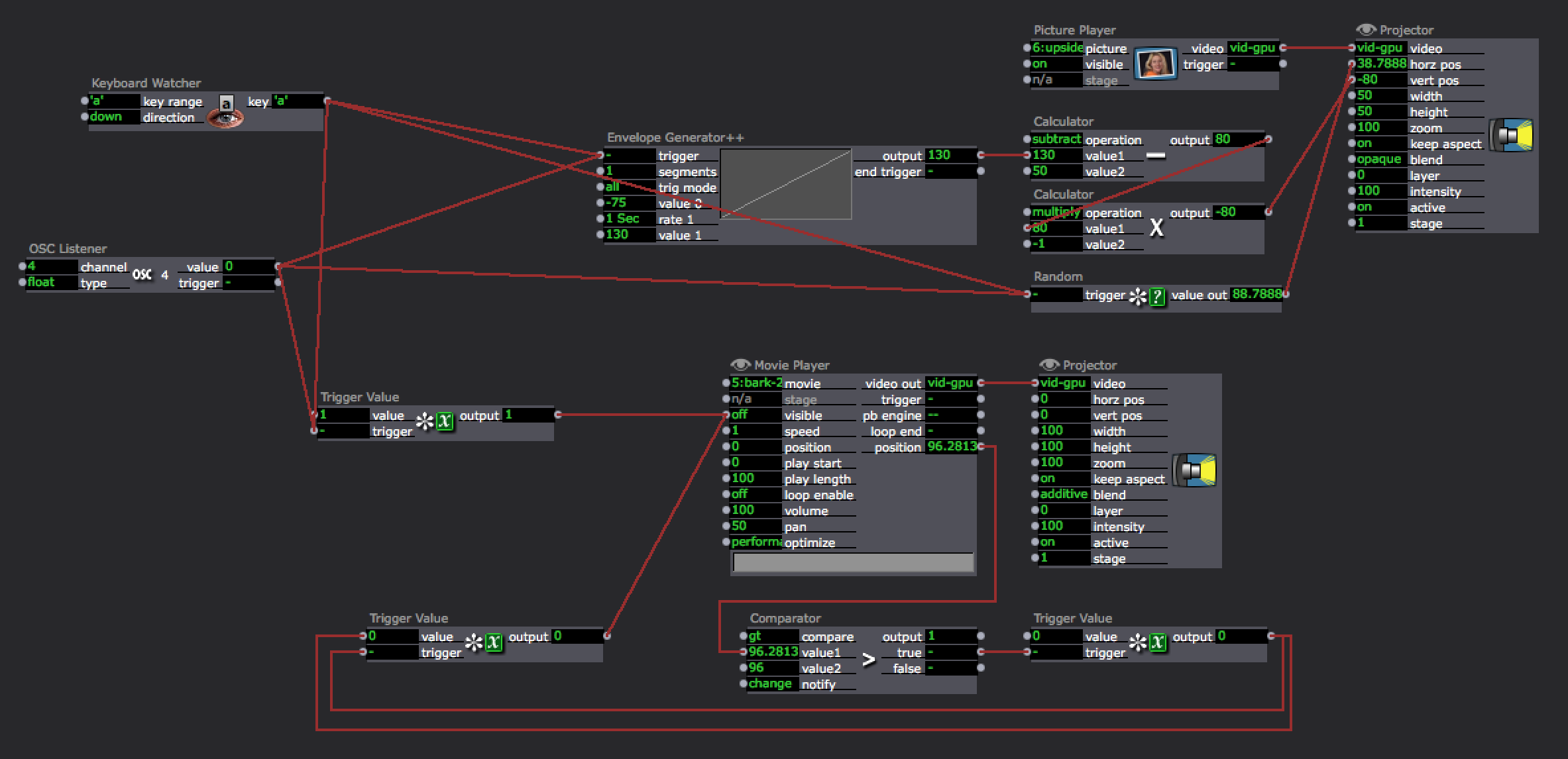
Phase two replaced the keyboard controls with the Leap controller. Using the Leap controller provides a more embodied experience—waving your hands in a mystical way versus pressing a button.
Setting up the Leap was simple. For whatever reason I could not get ManosOSC to talk with Isadora. I didn’t want to waste too much time, so I switched to Geco and was up and running in just a few minutes.
I then went through each scene and replaced the keyboard watchers with OSC listeners. I ran into several challenges here:
- The somewhat scattershot triggering of the OSC listeners sometimes confused Isadora. To solve this I inserted a few trigger delays, which slowed Isadora’s response time down enough so that errant triggers didn’t interfere with the system. I think that with more precise calibration of the LEAP and more closely defined listeners in Isadora I could eliminate this issue.
- Geco does not allow for recognition of individual fingers (the reason I wanted to use ManosOSC). Therefore, I had to leave the selector scene set up with keyboard watchers.
The last step in the process was to add user instructions in each scene so that it was clear how to progress through the experience. For example, “Thy right hand begins thy journey . . .”
My main takeaway from this project is that building individual scenes first and then connecting them after saves a lot of time. Had I tried to build the interactivity between scenes up front, I would have had to do a lot of reworking as the scenes themselves evolved. In a sense, the individual scenes in this project are resources in and of themselves, ready to be employed experientially however I want. I could easily go back and redo only the parameters of interactions between scenes and create an entirely new experience. Additionally, there is a lot of room in this experience for additional cues in order to help users move through the scenes, and for an aspect of randomness such that each user has a more individual experience.
Click to download the Isadora patch, Geco configuration, and supporting resource files:
http://bit.ly/2xHZHTO
The War on Buttons
Posted: September 11, 2017 Filed under: Uncategorized Leave a comment »https://www.theringer.com/tech/2017/9/11/16286158/apple-iphone-home-button
UPDATED READINGS – Sept. 2017
Posted: September 7, 2017 Filed under: Uncategorized Leave a comment »An updated list of readings:
10.1.1.60.1037 Understanding Knowledge Models: Modeling Assessment of Concept Importance in concept Maps
10.1.1.137.2955 The Theory Underlying Concept Maps and How to Construct and Use them
138041 The Bias of communication
A Simple Design Flaw Makes It Astoundingly Easy To Hack Siri And Alexa
Capturing experience- a matter of contextualising events
Frankfurt School_ The Culture Industry_ Enlightenment as Mass Deception
FultonSuriBuchenau-Experience_PrototypingACM_8-00 gladwell_twitter imageboards i
Oxman_THink Map 2004_Design-Studies P174-hollan
The_Hierarchy_of_Aesthetic_Experience
2017 Syllabus and Schedule [updated]
Posted: August 29, 2017 Filed under: Uncategorized Leave a comment »Hello all,
You can find the most up to date version of the syllabus and schedule here:
https://www.dropbox.com/s/4vyybc5b8mg67ia/ACCAD5194_Devising_EMS_Aut_2017.docx?dl=0
https://www.dropbox.com/s/ofofew8qpbbydui/T-Th_ACO_TV_DEMS_2017_Master_Schedule_v.2.docx?dl=0
Horse Bird Muffin Cycles
Posted: December 17, 2016 Filed under: Uncategorized Leave a comment »For my final project, I used Isadora, Vuo, a Kinect sensor, buttons and two projectors to create a sort of game or test to determine one’s inherent nature as horse, bird, or muffin, or some combination of them.
 Through a series of instructed interactions, a person first chooses an environment from 3 images projected onto a screen. As a person walks toward a particular image, their own moving silhouette is layered onto the image. Text appears to instruct them to move closer to the place they’ve chosen, and the closer they get, the louder an ambient sound associated with their chosen image gets.
Through a series of instructed interactions, a person first chooses an environment from 3 images projected onto a screen. As a person walks toward a particular image, their own moving silhouette is layered onto the image. Text appears to instruct them to move closer to the place they’ve chosen, and the closer they get, the louder an ambient sound associated with their chosen image gets.
Once within a certain proximity, if all goes well, the first part of the test is complete. So they start with a subtly, self-selected identity.
So they start with a subtly, self-selected identity.
In the next scene, the participant can interact with an image of their choice: the image mirrors their body moving through space and the image changes size based on the volume of sound the participant and their surroundings create. Stomping loud feet and claps make the image fill the screen and also earn the participant at least one horse ranking, while lot’s of traveling through space accumulates to earn the participants a bird ranking. Little or in place movement after a designated, as many guessed, puts them in ranks with muffins.





Any of the three events trigger a song affiliated with their rank and the next evaluation to begin.

This last scene never quite reached my imagined heights, but it was intended for the participant to see themselves on video in real time and delay, still with the moving silhouettes tracked and projected through a difference actor on Isadora. This worked and participants enjoyed dancing with themselves and their echoes onscreen. Parts that needed work were a few shapes actors that were designed to follow movements in different quadrants of the Kinect’s RGB camera field and a patch that counted the number of times the participant crossed a horizontal field completely (to trigger a final horse ranking) or moved from high to low in vertical field, or again, observed themselves with small or no movements until a set time was up.
These functions sometimes worked and did not demonstrate robustness….. 
Nonetheless, each participant was instructed to push a button at the end of their assessment and were able to discover if they were a birdhorsemuffin, a birdhorsehorse, triple horse or some other combination.


Pressure Project 3: Only the Lonely
Posted: December 16, 2016 Filed under: Uncategorized Leave a comment »For the third pressure project involving dice, I wanted the dice to trigger a music player, with the location of where dice landed determining which instrumental parts of a song would play. I decided to use a Kinect’s depth sensor to detect the presence of dice in the foreground, mid-ground and background of a marked range of space.
I made origami cubes to use as dice so that they were a bit larger and easy to detect and also not as volatile and thereby easier to keep within the range I’d set.
Using a Syphon Receiver in communication with Vuo, I connected the computer vision to 3 discrete ranges of depth and used a crop actor to cut out any information about objects, like people, that might come into the camera’s field of vision.
(This only partially worked and could use some fine tuning). In retrospect, I wonder if there is an adjustment on Eyes ++ I could use to require the presence of an object to last a certain amount of time before registering its brightness in order to prevent interfering messages besides the location of dice. 
Each Eyes actor was connected to a smoother and an inside range actor which looked for the brightness detected within the set luminescent range for each one to reach a minimum in order to trigger a series of signals. The primary signal was to play that sections sound (because the brightness indicated an object present) or to stop it (because below minimum brightness indicated the absence of an object).
Because the three instrumental music files were designed to play together, it was possible for 3 dice to land in the 3 respective ranges, with the goal being that all three files started together, playing a song with drums, bass line and keyboard melody (reminiscent of Roy Orbison’s Only the Lonely). To make this work and not have the sound files start in split seconds of each others, I set up a system of simultaneity actors, trigger delays and gates, that I can’t actually explain in detail, but I understand conceptually as delaying action to look first for simultaneous presence of objects in multiple ranges, then sending a signal for 2 or all based on information gathered, and barring that, continuing signals through for an individual part to play.
For example, if a dice landed in the mid-ground and 2 in the foreground, the inside range enter triggers from both those ranges would send triggers to individual trigger delays that in 2 seconds send a message to play a single file. BUT, if the simultaneity actor for the mid-ground and foreground is triggered, it signals a gate to turn off on those two delays, preventing the individual file triggers and sending a shared trigger to both the bass and the piano files to start at the same time.
For whatever reason I can only get a zip file of garageband file to upload, but this is all 3 parts together: dice-player-band
The entire Isadora patch is here: http://osu.box.com/s/eyjn9zge850ywc81yhdoj4cpbic1rkka
Chance music….