Cycle 3: Dancing with Cody Again – Mollie Wolf
Posted: December 15, 2022 Filed under: Uncategorized | Tags: dance, Interactive Media, Isadora, kinect, skeleton tracking Leave a comment »For Cycle 3, I did a second iteration of the digital ecosystem that uses an Xbox Kinect to manipulate footage of Cody dancing in the mountain forest.
Ideally, I want this part of the installation to feel like a more private experience, but I found out that the large scale of the image was important during Cycle 2, which presents a conflict, because that large of an image requires a large area of wall space. My next idea was to station this in a narrow area or hallway, and to use two projectors to have images on wither side or surrounding the person. Cycle 3 was my attempt at adding another clip of footage and another mode of tracking in order to make the digital ecosystem more immersive.
For this, I found some footage of Cody dancing far away, and thought it could be interesting to have the footage zoom in/out when people widen or narrow their arms. In my Isadora patch, this meant changing the settings on the OpenNI Tracker to track body and skeleton (which I hadn’t been asking the actor to do previously). Next, I added a Skeleton Decoder, and had it track the x position of the left and right hand. A Calculator actor then calculates the difference between these two numbers, and a Limit-Scale Value actor translates this number into a percentage of zoom on the Projector. See the images below to track these changes.
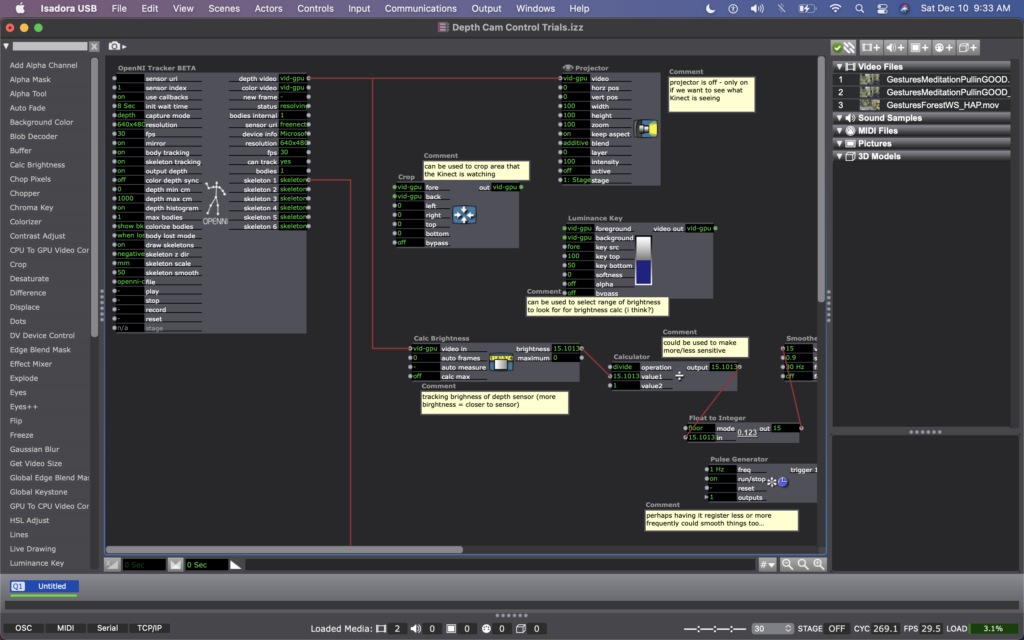
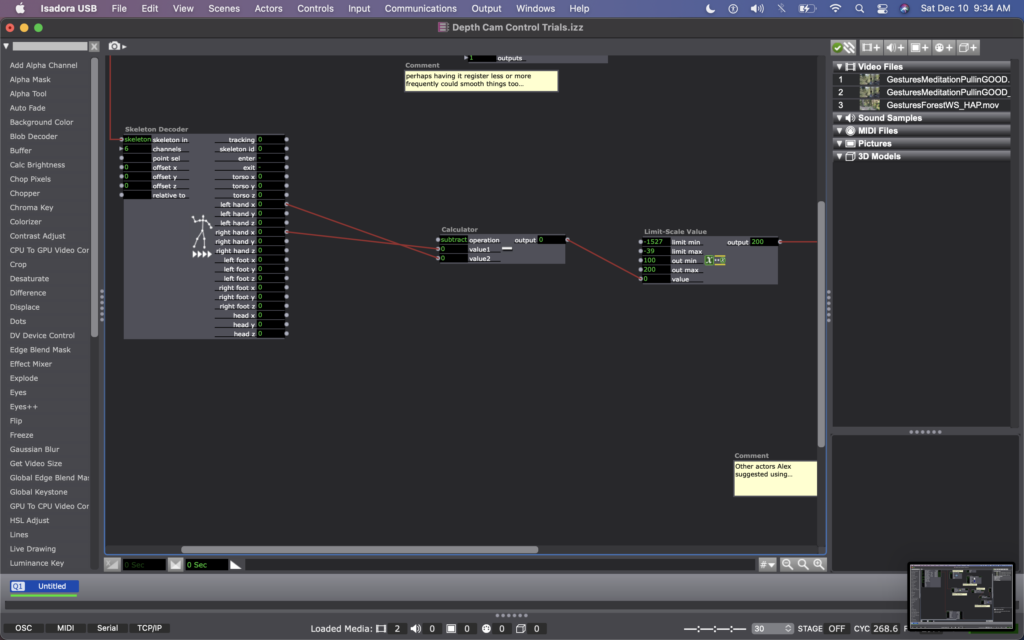
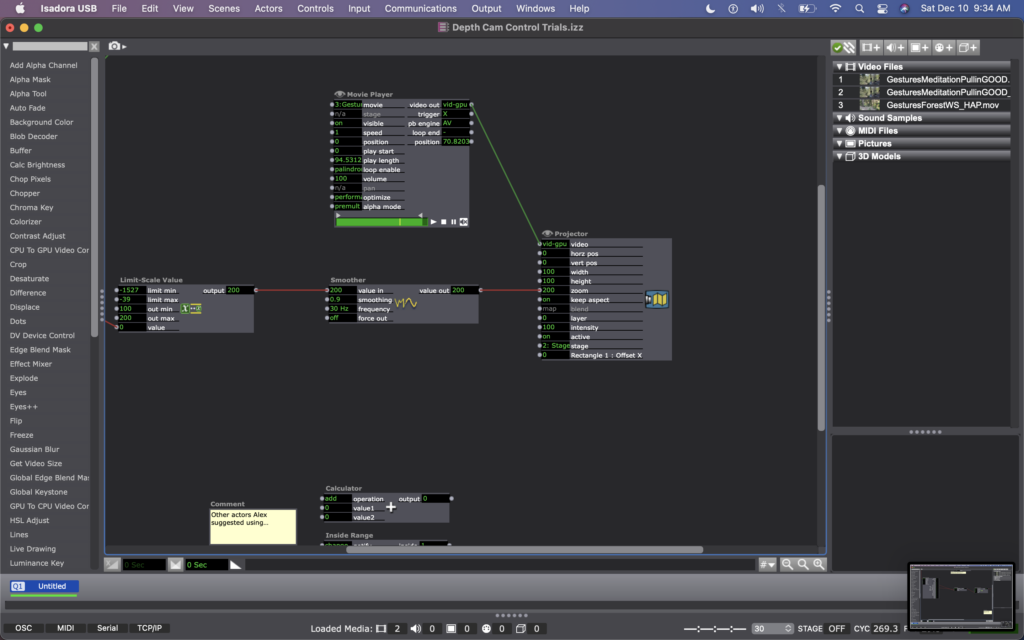
My sharing for Cycle 3 was the first time that I got to see the system in action, so I immediately had a lot of notes/thoughts for myself (in addition to the feedback from my peers). My first concern is that the skeleton tracking is finicky. It sometimes had a hard time identifying a body – sometimes trying to map a skeleton on other objects in space (the mobile projection screen, for example). And, periodically the system would glitch and stop tracking the skeleton altogether. This is a problem for me because while I don’t want the relationship between cause and effect to be obvious, I also want it to be consistent so that people can start to learn how they are affecting the system over time. If it glitches and doesn’t not always work, people will be less likely to stay interested. In discussing this with my class, Alex offered an idea that instead of using skeleton tracking, I could use the Eyes++ actor to track the outline of a moving blob (the person moving), and base the zoom on the width or area that the moving blob is taking up. This way, I could turn off skeleton tracking, which I think is part of why the system was glitching. I’m planning to try this when I install the system in Urban Arts Space.
Other thoughts that came up when the class was experimenting with the system were that people were less inclined to move their arms initially. This is interesting because during Cycle 2, people has the impulse to use their arms a lot, even though at the time the system was not tracking their arms. I don’t fully know why people didn’t this time. Perhaps because they were remembering that in Cycle 2 is was tracking depth only, so they automatically starting experimenting with depth rather than arm placement? Also, Katie mentioned that having two images made the experience more immersive, which made her slow down in her body. She said that she found herself in a calm state, wanting to sit down and take it in, rather than actively interact. This is an interesting point – that when you are engulfed/surrounded by something, you slow down and want to receive/experience it; whereas when there is only one focal point, you feel more of an impulse to interact. This is something for me to consider with this set up – is leaning toward more immersive experiences discouraging interactivity?
This question led me to challenge the idea that more interactivity is better…why can’t someone see this ecosystem, and follow their impulse to sit down and just be? Is that not considered interactivity? Is more physical movement the goal? Not necessarily. However, I would like people to notice that their embodied movement takes effect on their surroundings.
We discussed that the prompting or instructions that people are given could invite them to move, so that people try movement first rather than sitting first. I just need to think through the language that feels appropriate for the context of the larger installation.
Another notable observation from Tamryn was that the Astroturf was useful because it creates a sensory boundary of where you can move, without having to take your eyes off the images in front of you – you can feel when you’re foot reaches the edge of the turf and you naturally know to stop. At one point Katie said something like this: “I could tell that I’m here [behind Cody on the log] in this image, and over there [where Cody is, faraway in the image] at the same time.” This pleased me, because when Cody and I were filming this footage, we were talking about the echos in the space – sometimes I would accidentally step on a branch, causing s snapping noise, and seconds later I would hear the sound I made bouncing back from miles away, on there other side of the mountain valley. I ended up writing in my journal after our weekend of filming: “Am I here, or am I over there?” I loved the synchronicity of Katie’s observation here and it made my wonder if I wanted to include some poetry that I was working on for this film…
Please enjoy below, some of my peers interacting with the system.