Cycle 3: Dancing with Cody Again – Mollie Wolf
Posted: December 15, 2022 Filed under: Uncategorized | Tags: dance, Interactive Media, Isadora, kinect, skeleton tracking Leave a comment »For Cycle 3, I did a second iteration of the digital ecosystem that uses an Xbox Kinect to manipulate footage of Cody dancing in the mountain forest.
Ideally, I want this part of the installation to feel like a more private experience, but I found out that the large scale of the image was important during Cycle 2, which presents a conflict, because that large of an image requires a large area of wall space. My next idea was to station this in a narrow area or hallway, and to use two projectors to have images on wither side or surrounding the person. Cycle 3 was my attempt at adding another clip of footage and another mode of tracking in order to make the digital ecosystem more immersive.
For this, I found some footage of Cody dancing far away, and thought it could be interesting to have the footage zoom in/out when people widen or narrow their arms. In my Isadora patch, this meant changing the settings on the OpenNI Tracker to track body and skeleton (which I hadn’t been asking the actor to do previously). Next, I added a Skeleton Decoder, and had it track the x position of the left and right hand. A Calculator actor then calculates the difference between these two numbers, and a Limit-Scale Value actor translates this number into a percentage of zoom on the Projector. See the images below to track these changes.
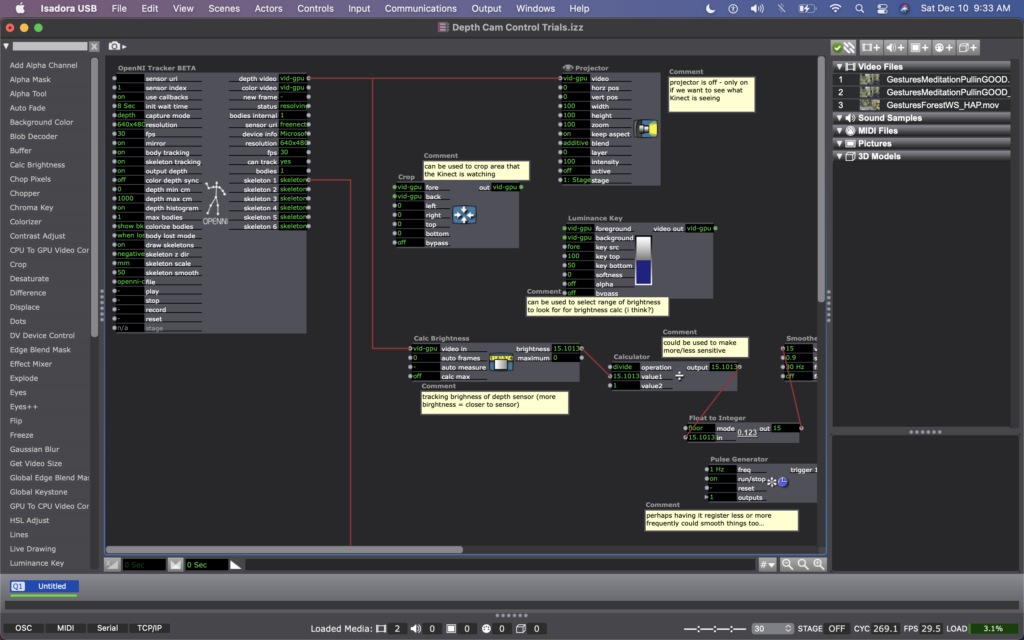
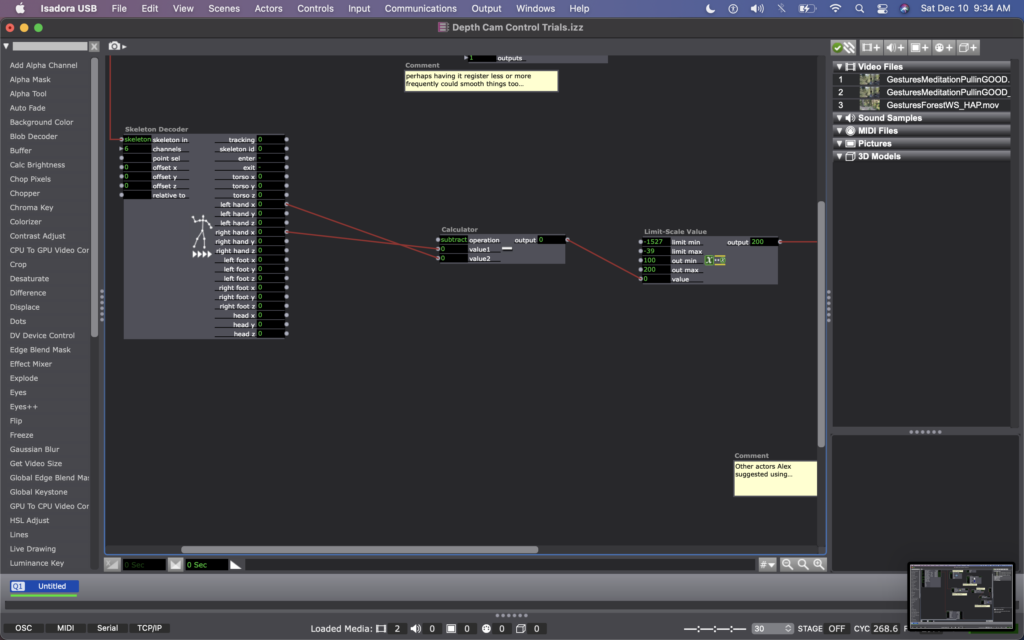
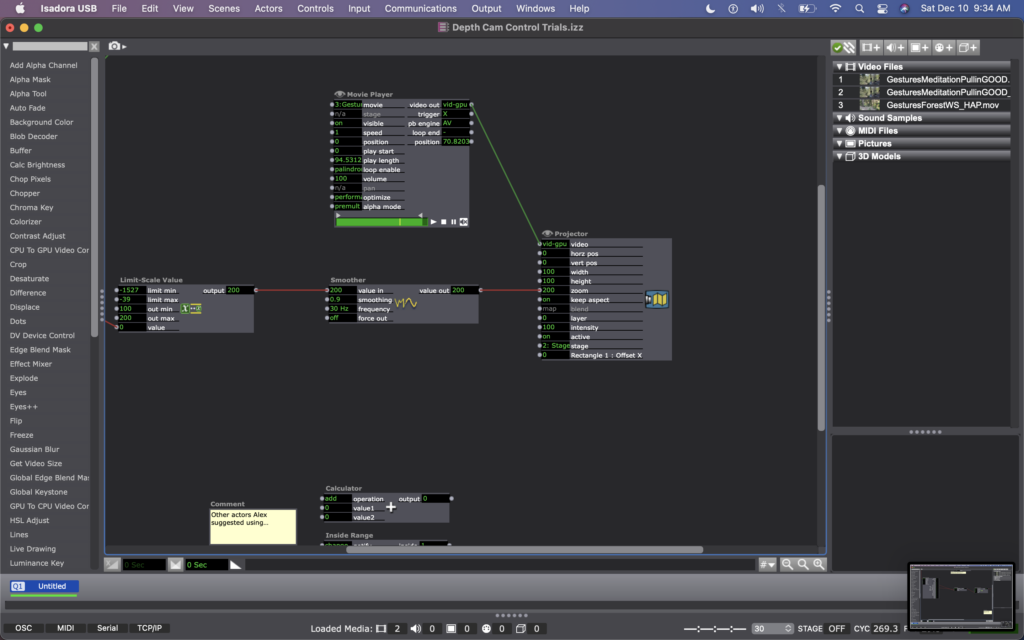
My sharing for Cycle 3 was the first time that I got to see the system in action, so I immediately had a lot of notes/thoughts for myself (in addition to the feedback from my peers). My first concern is that the skeleton tracking is finicky. It sometimes had a hard time identifying a body – sometimes trying to map a skeleton on other objects in space (the mobile projection screen, for example). And, periodically the system would glitch and stop tracking the skeleton altogether. This is a problem for me because while I don’t want the relationship between cause and effect to be obvious, I also want it to be consistent so that people can start to learn how they are affecting the system over time. If it glitches and doesn’t not always work, people will be less likely to stay interested. In discussing this with my class, Alex offered an idea that instead of using skeleton tracking, I could use the Eyes++ actor to track the outline of a moving blob (the person moving), and base the zoom on the width or area that the moving blob is taking up. This way, I could turn off skeleton tracking, which I think is part of why the system was glitching. I’m planning to try this when I install the system in Urban Arts Space.
Other thoughts that came up when the class was experimenting with the system were that people were less inclined to move their arms initially. This is interesting because during Cycle 2, people has the impulse to use their arms a lot, even though at the time the system was not tracking their arms. I don’t fully know why people didn’t this time. Perhaps because they were remembering that in Cycle 2 is was tracking depth only, so they automatically starting experimenting with depth rather than arm placement? Also, Katie mentioned that having two images made the experience more immersive, which made her slow down in her body. She said that she found herself in a calm state, wanting to sit down and take it in, rather than actively interact. This is an interesting point – that when you are engulfed/surrounded by something, you slow down and want to receive/experience it; whereas when there is only one focal point, you feel more of an impulse to interact. This is something for me to consider with this set up – is leaning toward more immersive experiences discouraging interactivity?
This question led me to challenge the idea that more interactivity is better…why can’t someone see this ecosystem, and follow their impulse to sit down and just be? Is that not considered interactivity? Is more physical movement the goal? Not necessarily. However, I would like people to notice that their embodied movement takes effect on their surroundings.
We discussed that the prompting or instructions that people are given could invite them to move, so that people try movement first rather than sitting first. I just need to think through the language that feels appropriate for the context of the larger installation.
Another notable observation from Tamryn was that the Astroturf was useful because it creates a sensory boundary of where you can move, without having to take your eyes off the images in front of you – you can feel when you’re foot reaches the edge of the turf and you naturally know to stop. At one point Katie said something like this: “I could tell that I’m here [behind Cody on the log] in this image, and over there [where Cody is, faraway in the image] at the same time.” This pleased me, because when Cody and I were filming this footage, we were talking about the echos in the space – sometimes I would accidentally step on a branch, causing s snapping noise, and seconds later I would hear the sound I made bouncing back from miles away, on there other side of the mountain valley. I ended up writing in my journal after our weekend of filming: “Am I here, or am I over there?” I loved the synchronicity of Katie’s observation here and it made my wonder if I wanted to include some poetry that I was working on for this film…
Please enjoy below, some of my peers interacting with the system.
Mollie Wolf Cycle 2: The WILDS – Dancing w/ Cody
Posted: November 27, 2022 Filed under: Uncategorized | Tags: depth camera, Interactive Media, Isadora, kinect, mollie wolf Leave a comment »For Cycle 2, I began experimenting with another digital ecosystem for my thesis installation project. I began with a shot I have of one of my collaborators, Cody Brunelle-Potter dancing, gesturing, casting spells on the edge of a log over looking a mountain side. As they do so, I (holding the camera) am slowing walking toward them along the log. I was rewatching this footage recently with the idea of using a depth camera to play the footage forward or backward as you walk – allowing your body to mimic the perspective of the camera – moving toward Cody or away from them.

I wasn’t exactly sure how to make this happen, but the first idea I came up with was to make an Isadora patch that recorded how far someone was from an Xbox Kinect at moments in time regularly, and was always comparing the their current location to where they were a moment ago. Then, whether the difference between those two numbers was positive or negative would tell the video whether to play forward or backward.
I explained this idea to Alex; he agreed it was a decent one and helped me figure out which actors to use to do such a thing. We began with the OpenNI Tracker, which has many potential ways to track data using the Kinect. We turned many of the trackers off, because I wasn’t interested in creating any rules in regards to what the people were doing, just where they were in space. The Kinect sends data by bouncing a laser of objects, depending on how bright the is when it bounces back tells the camera whether the object is close (bright), or far (dim). So the video data that comes from the Kinect is grey scale, based on this brightness (closer is to white, as far is to black). To get a number from this data, we used a Calc Brightness actor, which tracks a steadily changing value corresponding to the brightness of the video. Then we used Pulse Generator and Trigger Value actors to frequently record this number. Finally, we used two Comparator actors: one that checked if the number from the Pulse Generator was less than the current brightness from the Calc Brightness actor, and one that did the opposite, if it was greater than. These Comparators each triggered Tigger Value actors that would trigger the speed of the Movie Player playing the footage of Cody to be -1 or 1 (meaning that it would play forward at normal speed or backwards at normal speed).
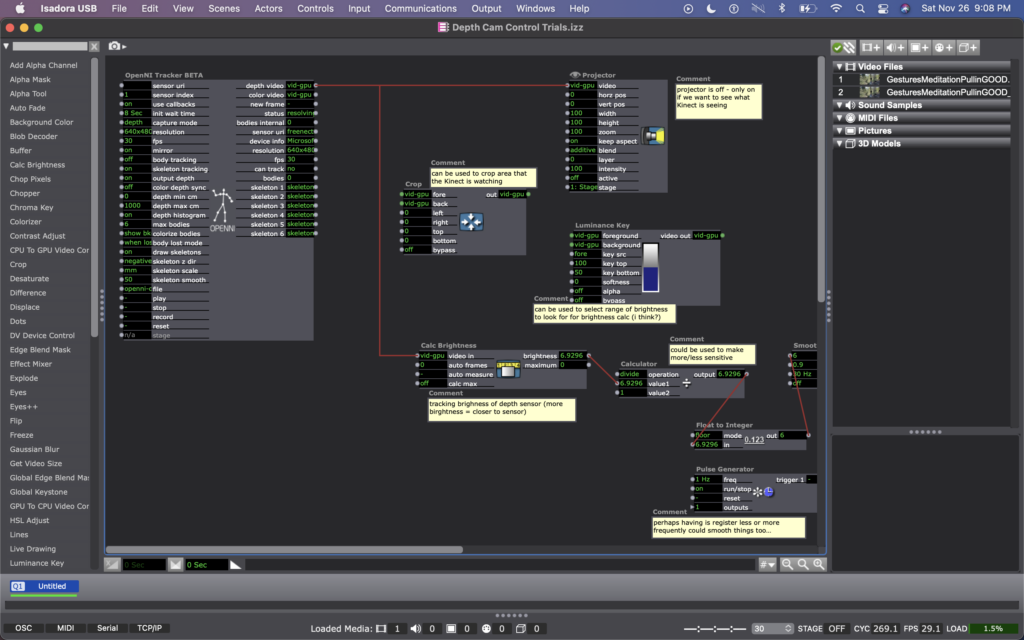
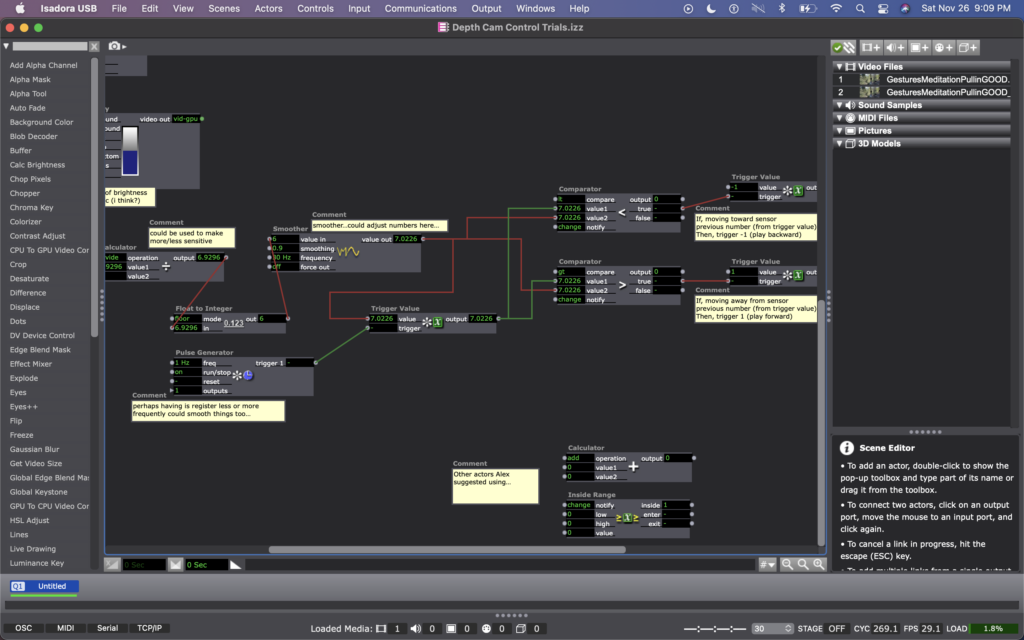
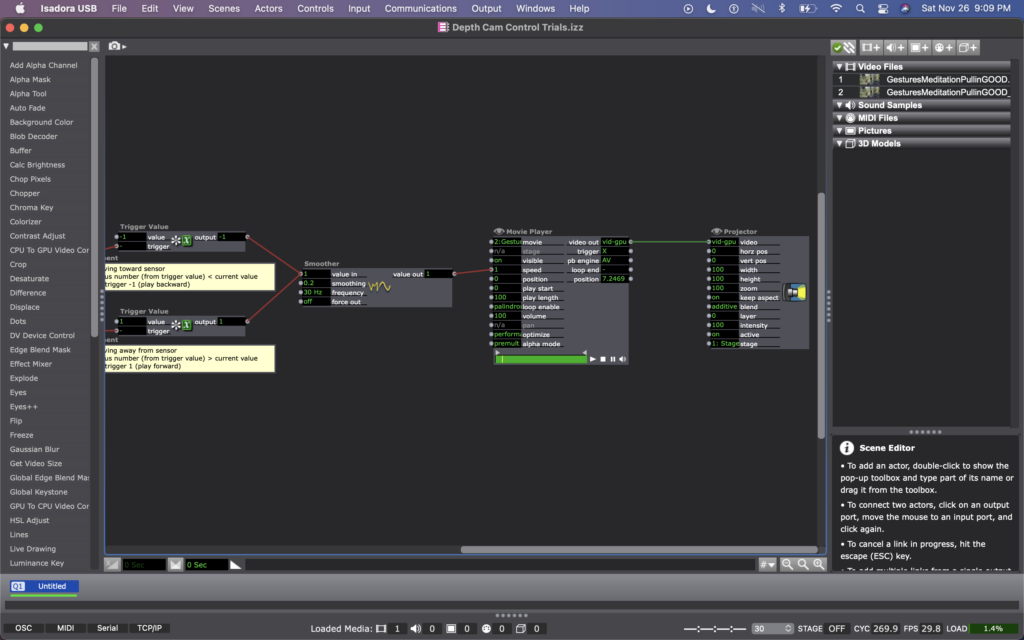
Once this basic structure was set up, quite a bit of fine tuning was needed. Many of the other actors you see in these photos were used to experiment with fine tuning. Some of them are connect and some of them are not. Some of them are even connected but not currently doing anything to manipulate the data (the Calculator, for example). At the moment, I cam using the Float to Integer actor to make whole numbers out of the brightness number (as opposed to one with 4 decimal points). This makes the system less sensitive (which was a goal because initially the video would jump between forward and backward when a person what just standing still, breathing). Additionally I am using a Smoother in two locations, one before the data reaches the Trigger Value and Comparator actors, and one before the data reaches the Movie Player. In both cases, the Smoother creates a gradual increase or decrease of value between numbers rather than jumping between them. The first helps the sensed brightness data change steadily (or smoothly, if you will); and the second helps the video slow to a stop and then speed up to a reverse, rather than jumping to reverse, which felt glitchy originally. As I move this into Urban Arts Space, where I will ultimately be presenting this installation, I will need to fine tune quite a bit more, hence why I have left the other actors around as additional things to try.
Once things were fine tuned and functioning relatively well, I had some play time with it. I noticed that I almost instantly had the impulse to dance with Cody, mimicking their movements. I also knew that depth was what the camera was registering, so I played a lot with moving forward and backward at varying times and speeds. After reflecting over my physical experimentation, I realized I was learning how to interact with the system. I noticed that I intuitively changed my speed and length of step to be one that the system more readily registered, so that I could more fluidly feel a responsiveness between myself and the footage. I wondered whether my experience would be common, or if I as a dancer have particular practice noticing how other bodies are responding to my movement and subtly adapting what I’m doing in response to them…
When I shared the system with my classmates, I rolled out a rectangular piece of astro turf in the center of the Kinect’s focus (and almost like a carpet runway pointing toward the projected footage of Cody). I asked them to remove their shoes and to take turns, one at a time. I noticed that collectively over time they also began to learn/adapt to the system. For them, it wasn’t just their individual learning, but their collective learning because they were watching each other. Some of them tried to game-ify it, almost as thought it was a puzzle with an objective (often thinking it was more complicated than it was). Others (mostly the dancers) had the inclination to dance with Cody, as I had. Even though I watched their bodies learned the system, none of them ever quite felt like they ‘figured it out.’ Some seemed unsettled by this and others not so much. My goal is for people to experience a sense of play and responsiveness between them and their surroundings, less that it’s a game with rules to figure out.
Almost everyone said that they enjoyed standing on the astro turf—that the sensation brought them into their bodies, and that there was some pleasure in the feeling of stepping/walking on the surface. Along these lines, Katie suggested a diffuser with pine oil to further extend the embodied experience (something I am planning to do in multiple of the digital ecosystems through out the installation). I’m hoping that prompting people into their sensorial experience will help them enter the space with a sense of play, rather than needing to ‘figure it out.’
I am picturing this specific digital ecosystem happening in a small hallway or corner in Urban Arts Space, because I would rather this feel like an intimate experience with the digital ecosystem as opposed to a public performance with others watching. As an experiment with this hallway idea, I experimented with the zoom of the projector, making the image smaller or larger as my classmates played with the system. Right away, my classmates and I noticed that we much preferred the full, size of the projector (which is MUCH wider than a hallway). So now I have my next predicament – how to have the image large enough to feel immersive in a narrow hallway (meaning it will need to wrap on multiple walls).
Cycle 1 – Ghosts in the Landscape – Mollie Wolf
Posted: November 2, 2022 Filed under: Uncategorized Leave a comment »For cycle 1, I decided to attempt an interactive portion of my installation. My initial idea was to use an Astra or Kinect, with a depth sensor to make the background invisible and layer live capture footage of audience members into a video of a landscape.
When I asked Alex for help in background subtraction, he suggested I use a webcam instead. We found an example patch that Mark had posted on Toikatronix for background subtraction, so I started there.
He essentially used an effects mixer with a threshold actor to read the data from a video in watcher, and identify when a person had entered the frame – by watching for a change in light, compared to a freeze frame grab of the same image. Then, he used an add alpha channel actor to mask anything that hadn’t changed (i.e. the background).
Here are photos of my version of Mark’s background subtraction patch.
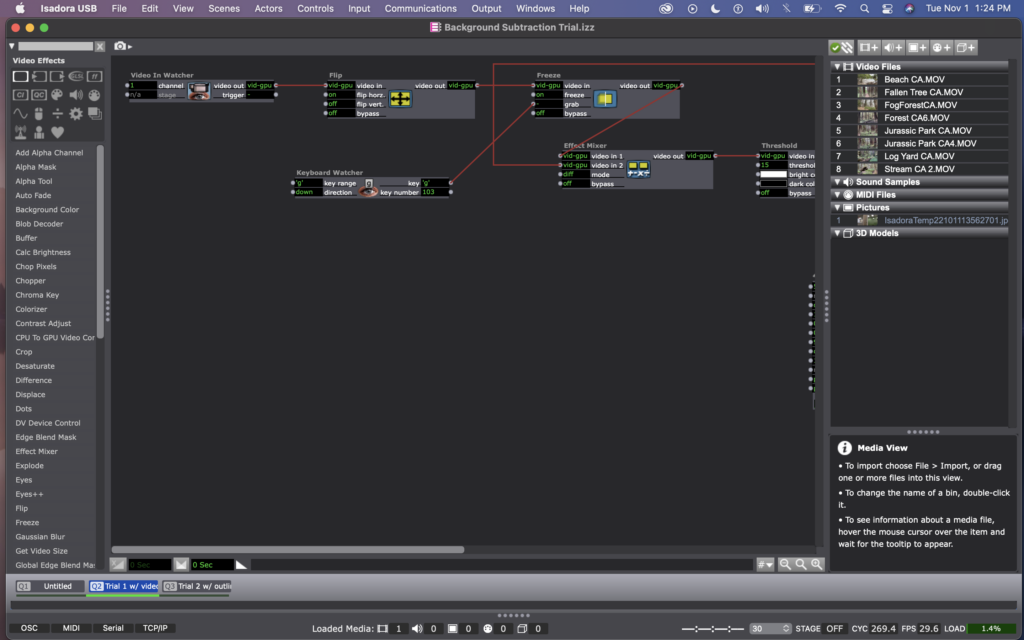
When I was first using this patch, it was a little finicky – sometimes only showing portions of the body, or flickering images of the background, or showing splotchy images. I noticed that it had a hard time with light colors (if the person was wearing white, as well as if their skin was reflecting the light in the room). I tried to fix this by adjusting the threshold number and by adding a gaussian blur to the image, but it still was more finicky than I’d like.
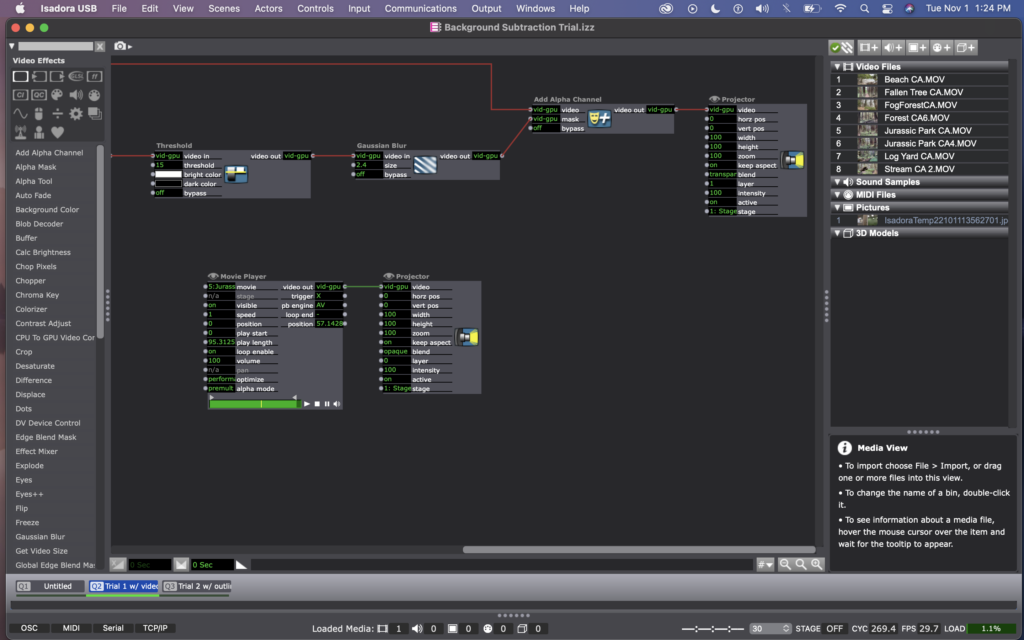
When I brought this issue up to Alex, he suggested that I could use a difference actor instead to do something similar. However, with the difference actor, it is mostly recognizing the outline of bodies rather than picking up the whole image of a person. I decided that I actually liked this better, aesthetically anyway – it made for ghost-like images to be projected in to the landscape, rather than video images of the people.
Here are photos of my current patch, using a difference actor. (The top line with the flip, freeze, effect mixer, etc – is still there from the previous attempt, but the projector is not active, so you can ignore that).
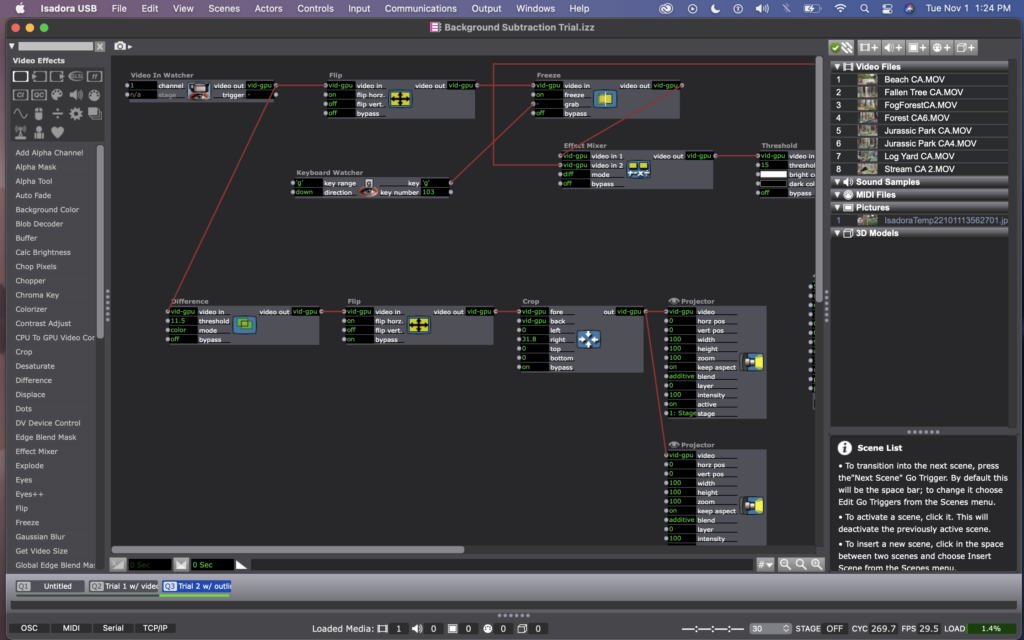
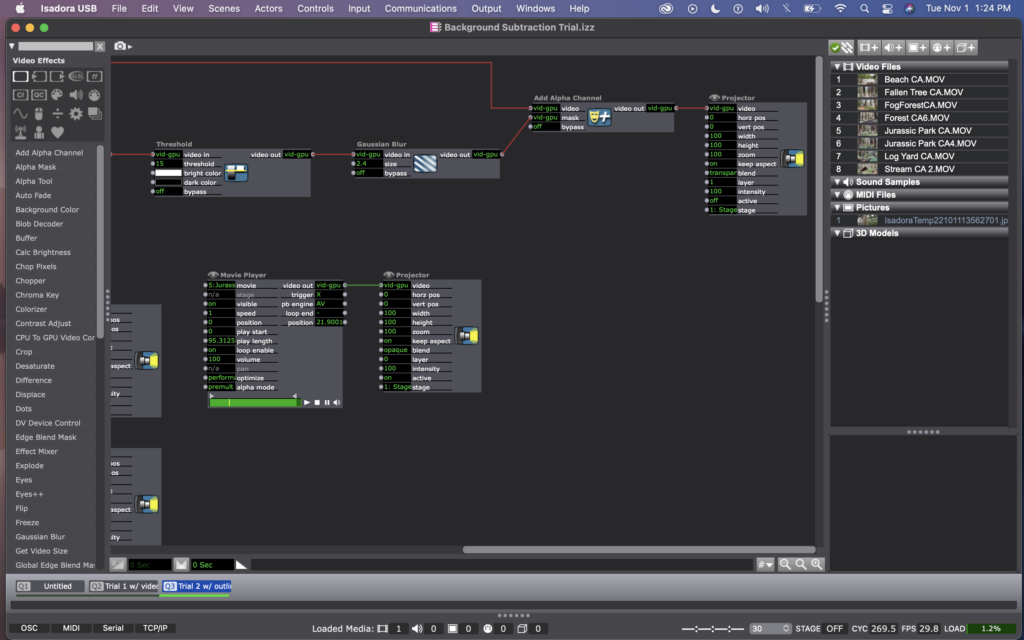
I think this method worked way better because it was no longer dependent on light in the room, and instead just on motion. (Which is way better for me, considering that I’m practicing this all in the Motion Lab with black walls and floors, but will be presenting it in Urban Arts Space with white walls and concrete floors). Conceptually, I like this version more as well, as it is an abstraction of people’s bodies and action, rather than a direct representation of it.
As a last minute experimentation, I laid out some platforms in the space and roughly lined them up with where there were mounds/hills in the landscape – that way if someone stood on the platform, it would look like their corresponding ghost image had climbed up the hill.
When I presented this version to the class, I was pleased to see how playful everyone became. With it just being an outline of their bodies, they were not looking at an image of themselves, and so there didn’t seem to be any amount of self-consciousness that I would expect if everyone were looking in a mirror, for example. People seemed to have genuine delight in figuring out that they could move through the landscape.
One interesting thing about the difference actor, is that non-moving bodies blend into the background (with no motion, there is no difference, frame be frame). So when someone decides to sit or stand rather than moving around, their ghost image disappears. While this is an inevitable aspect of the difference actor, I kind of like the metaphor behind this – you have to actively, physically engage in order to take effect on your environment.
We spent some time with the camera in a few different locations (to the side or in front of people). As we were discussing together, we came to a consensus that it was more magical/interesting when the camera was to the side. It was a, less obvious in terms of how to move (i.e. not as easy as looking into a mirror), which added to the magic. And having the camera to the side also meant that the landscape image was not obscured from view by anything. People only knew where the camera was if they went searching for it.
Here is a video of my peers interacting with the patch/system.
PP2: Inviting Intimacy through Sonic Storytelling – Mollie Wolf
Posted: October 25, 2022 Filed under: Uncategorized Leave a comment »For this pressure project, I wanted to work toward my project for cycle 1, building the sonic storytelling element I’m been imagining. The idea I have in mind is to have some sort of cornered off/walled off space that feels private. Perhaps there will be a comfy chair here, perhaps there will be a small screen, playing a personal film for one person at a time, perhaps it will just be an area surrounded by plants, with only the sonic storytelling happening. The point is to create a sense of intimacy. A time when one audience member at a time can experience something between them and their real/imagined environment.
I used a few different sound recordings I have of Frankie Tan (my friend/collaborator whom I traveled to Malaysia with this summer) telling a story she wrote about herself and her relationship to the jungle in Penang. I decided that as time goes on, I wanted the sense of intimacy to increase, so I started with a recording of her speaking aloud, then slowly, by the time we reach the end of the story, she has transitioned into whispering to her listener. My plan is to play Frankie’s voice/story on a small, local speaker that only the one listener can hear – so that this truly is a moment that they alone get to experience.
Here is a recording of Frankie’s story (I started this audio at 3:57 when I did the presentation).
Then, I looped a sound recording I have of the Penang jungle at night to play through out a larger space, to really surround the listener (the individual one, as well as others in surrounding areas) with the sounds of the jungle that Frankie’s story references.
Here is a recording of the Penang jungle.
When I presented the story to my peers, I didn’t let them know about my goal of intimacy, and I presented it to all of them at once. I placed the Bluetooth speaker with Frankie’s story nearby where my audience was sitting, and played the jungle sounds through the whole room.
Here is a recording of the two playing together, in the same space.
I was pleased to know that the sense of intimacy was apparent to my audience. Some of them mentioned wanting to be closer to the speaker and having the impulse to ‘lean in.’ One of my peers said that the content of the story felt like an intimate conversation between this person (Frankie’s character, Noon) and the forest.
Alex mentioned that there was more than just intimacy, but also tension – he noticed the word ‘hate.’ I appreciate this as well, because it is purposeful. So much of my thesis project in general is about this – the concept of ‘the wild,’ this simultaneous allure and repulsion that we feel about the natural world, and the behaviors and concepts we have been socialized into that create a distance between ourselves and nature. There is a love/hate present. There is an internal struggle for the Western body between desire, responsibility, and ignorance when it comes to ‘the wild,’ so absolutely yes, the tension in this story is purposeful. Intimacy does not mean a lack of tension.
Feedback that I want to keep in mind from my peers is that it was confusing, or hard to follow, or distracting when I had Frankie’s voice layer over itself. I wonder if there is a way I can either play with it more, so it feels like it’s okay that you’re not catching every word, or if I should just not layer her voice at all…
PP1 Playing with Randomness – Mollie Wolf
Posted: September 11, 2022 Filed under: Uncategorized Leave a comment »For this pressure project, I decided to use continue using the random shapes demo we worked on together as a class, and layered onto it/made it more complex.
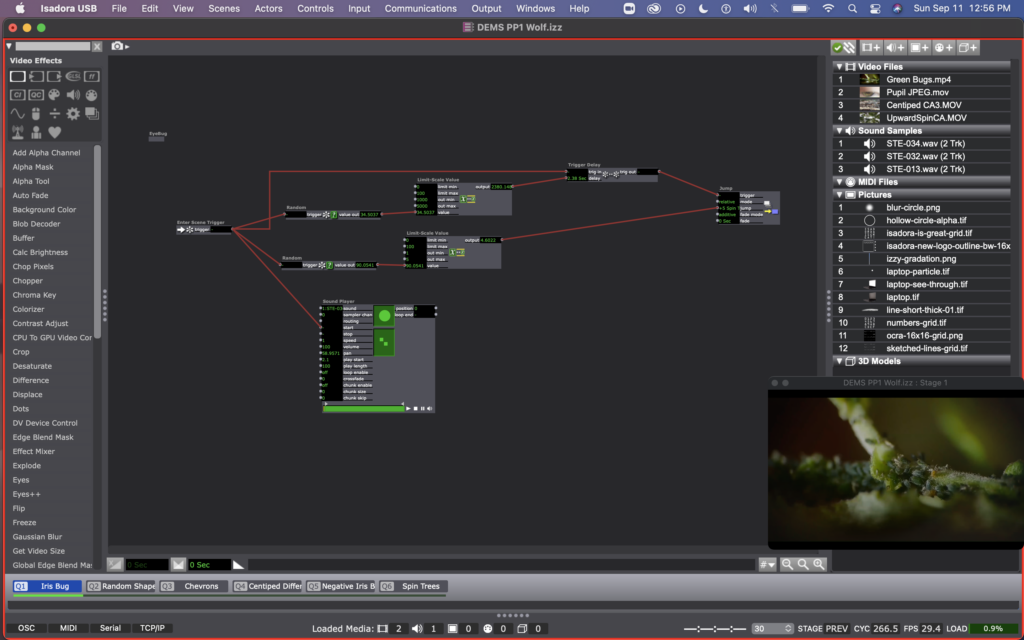
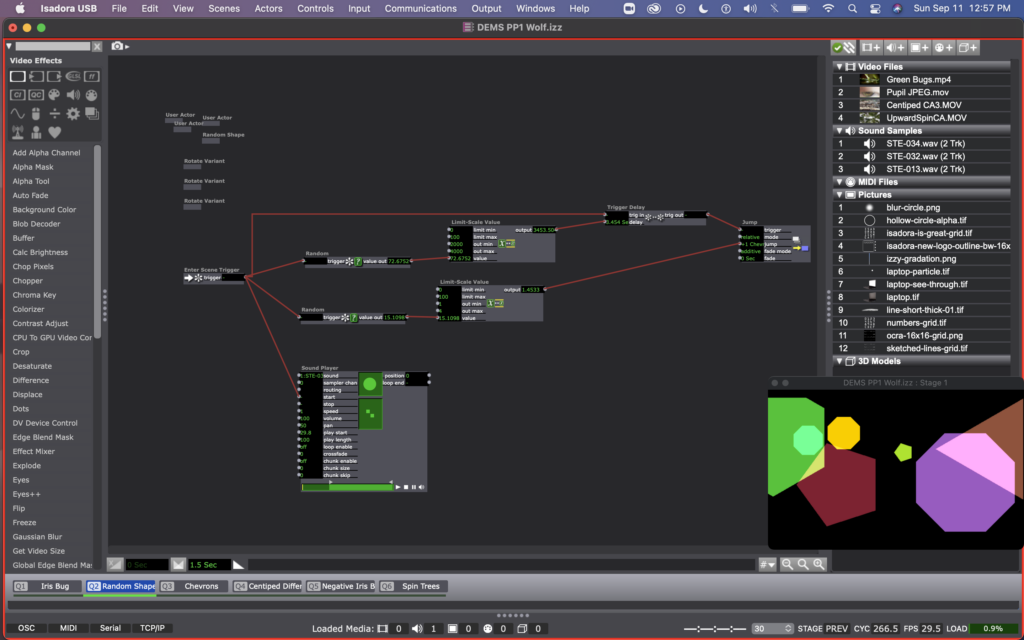
I leaned into the randomness prompt quite a bit, and decided to use random actors to decide how long the patch would stay in each scene, as well as which scene it would jump to next. You can see this clearly in this photo of Scene 1, where one random actor is determining the delay time on a trigger delay actor, and another random actor is hooked up to the jump location on the jump actor. I repeated this process for every scene in order to make it a self generating patch that cycles through the scenes endlessly in randomized order.
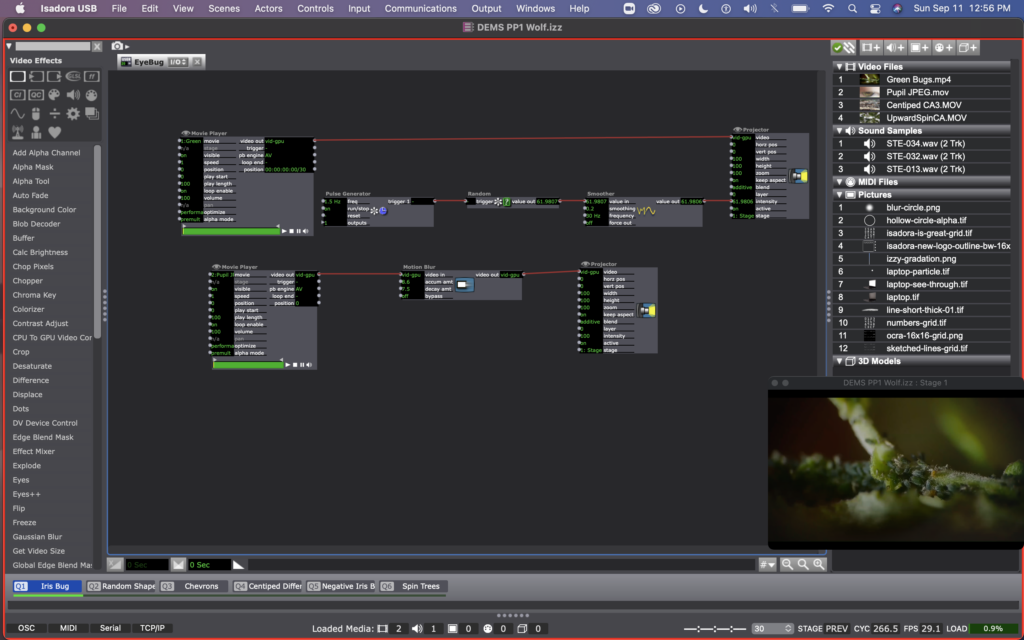
In scene 1, I was playing with the videos that Mark included in his guru sessions. I used a pulse generator, random actor, and smoother to have the intensity of the bugs video fade in and out. Then I used a motion blur actor on the pupil video to exaggerate the trippy vibe that was happening every time they blinked or refocused their eye.
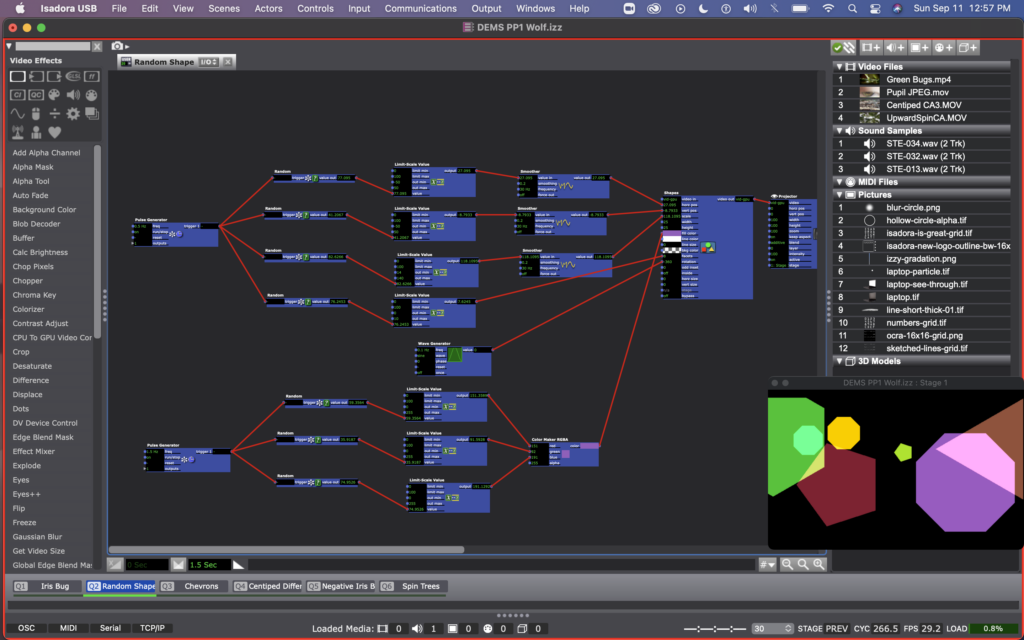
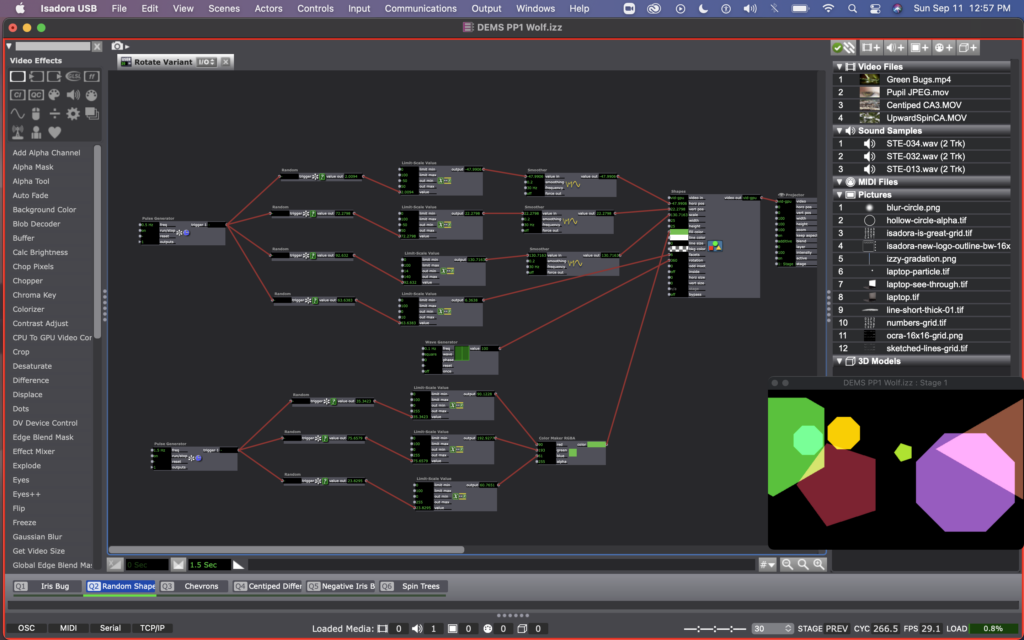
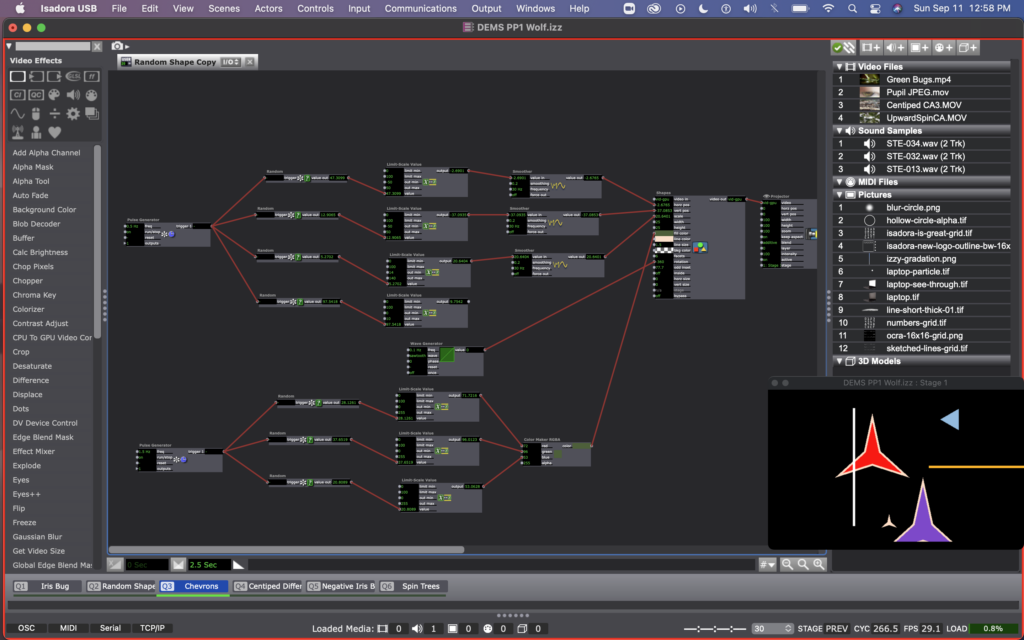
I kept the shape user actors I was playing with in class last week in two of my scenes (Q2 & Q3). With these shapes I was experimenting with a variety of things – all determined still by using random actors. In the shapes created be the user actor called “Random Shape,” random actors are determining the facet number, color, and position of the shapes, and a wave generator is determining the rotation of them. I like the effect of the smoother here so that the shapes looking like they are moving, rather than jumping from place to place. At one point I noticed that they were all rotating together (since they all had the same wave generator affecting them, so I created a variant of this user actor, called “Rotation Variant” with a different wave generator (square rather than sine).
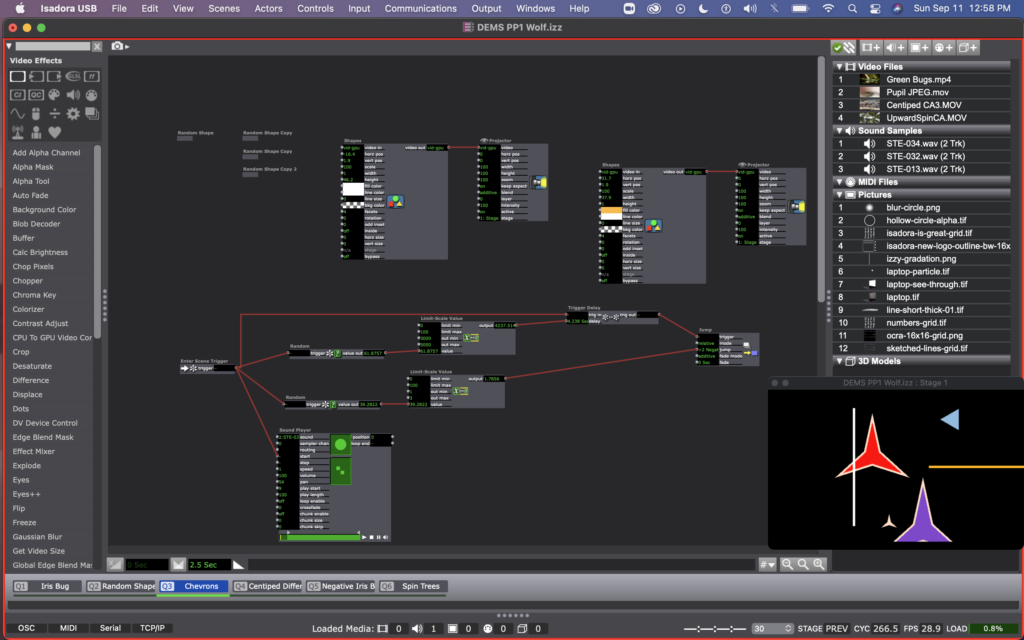
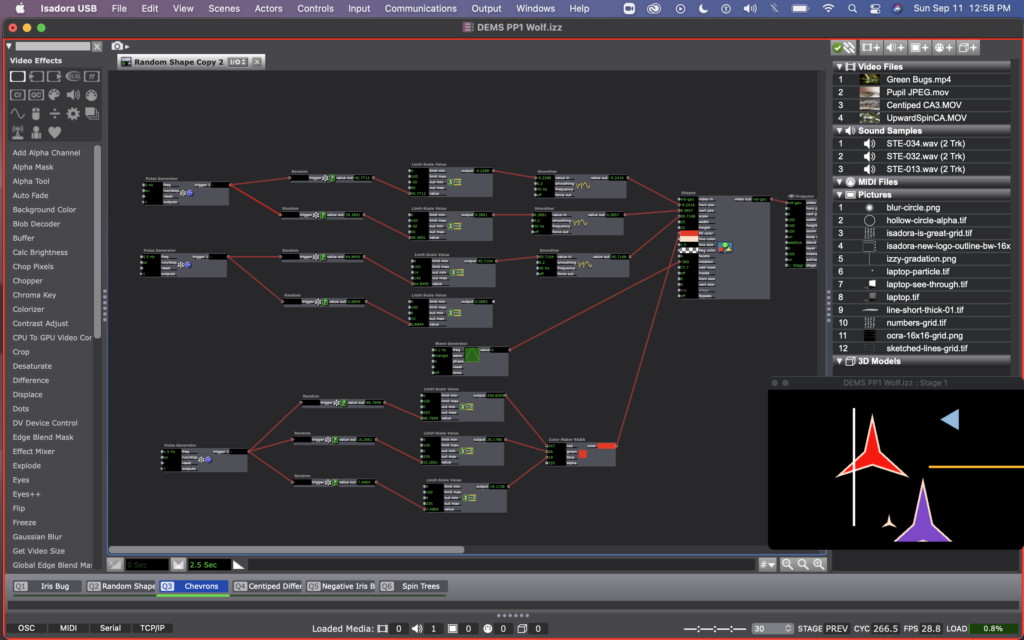
In scene 3, I edited these user actors further. I made a variation of this user actor, called “Random Shape Copy,” in which all the shapes have 6 facets (making a chevron-esc shape), and are using the sawtooth wave generator for rotation. And just so not all the shapes in this scene were rotating in unison, I created a copy of of this user actor, called “Random Shape Copy 2” that used a triangle wave generator for rotation instead. I also added a couple static lines with shape actors in this scene so that the shapes would look like they were crossing thresholds as they moved across the stage.
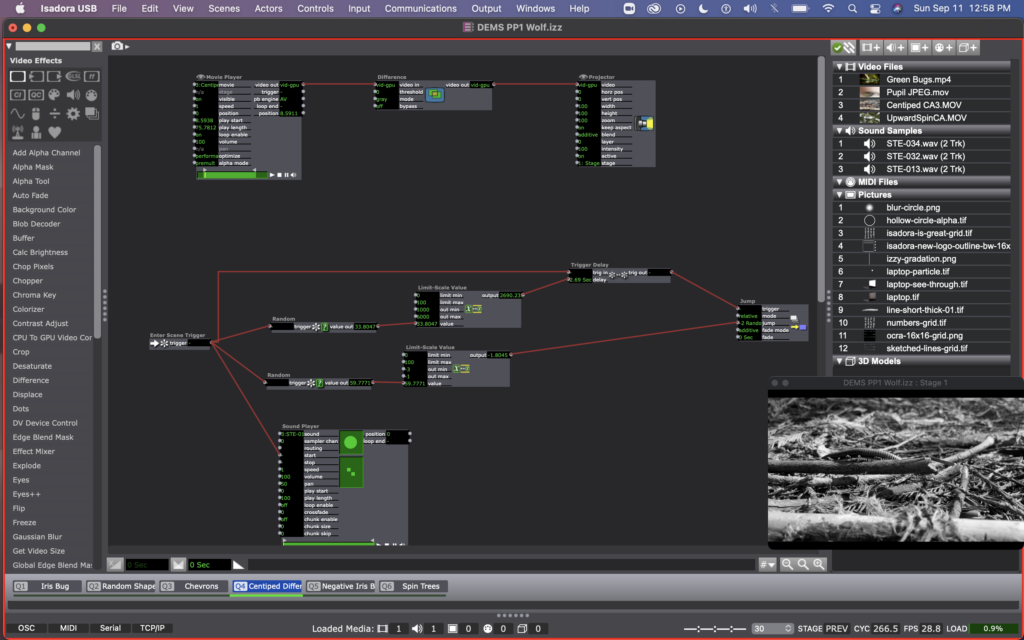
Once I figured out how to jump between scenes, I decided to experiment with some footage I have for my thesis. You can see me starting this in scene 4, where I used a difference actor to create an X-ray esc version of a video of a centipede crawling. I also started to add sound to the scenes at this point (even going back and adding sound to my previous 3 scenes as well). The sound is triggered by the enter scene trigger and has a starting point that is individual for each scene (determined by the arrows on the sound player actor).
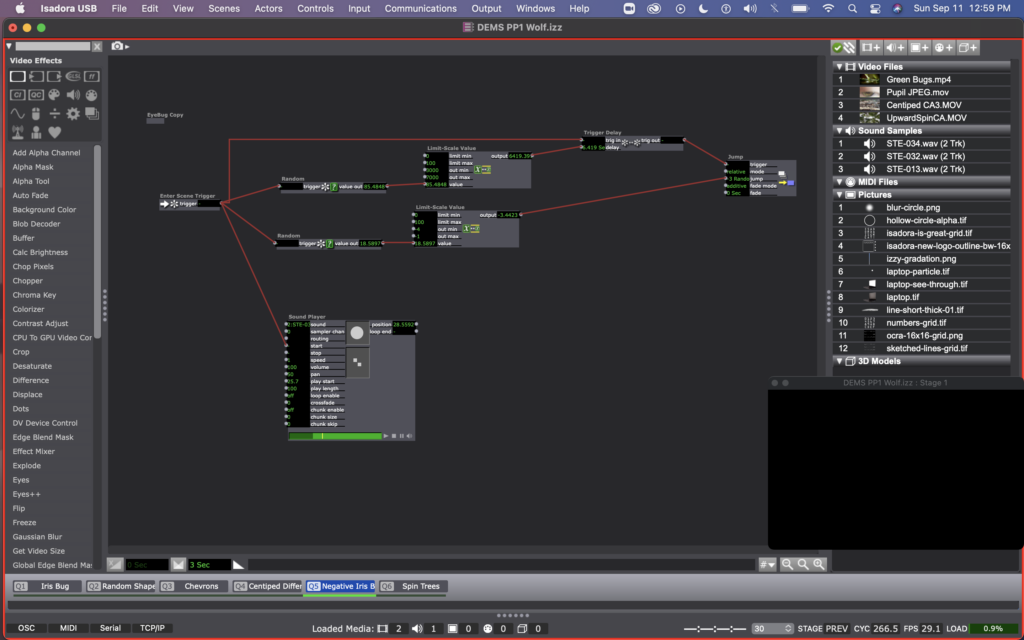
For scene 5, I copied the user actor I created in scene 1, calling the copy “EyeBug Copy.” Here you can see that I inserted a video inverter between the movie player and projector for the iris video. Then, I used random actors and a pulse generator to determine and regularly change the invert color. I added a sound file here – the same that I used in other scenes, but set the start location for a sound bit that mentions looking into the eyes of a shrieking macaque, which I thought was an appropriate pairing for a colorized video of an eye.
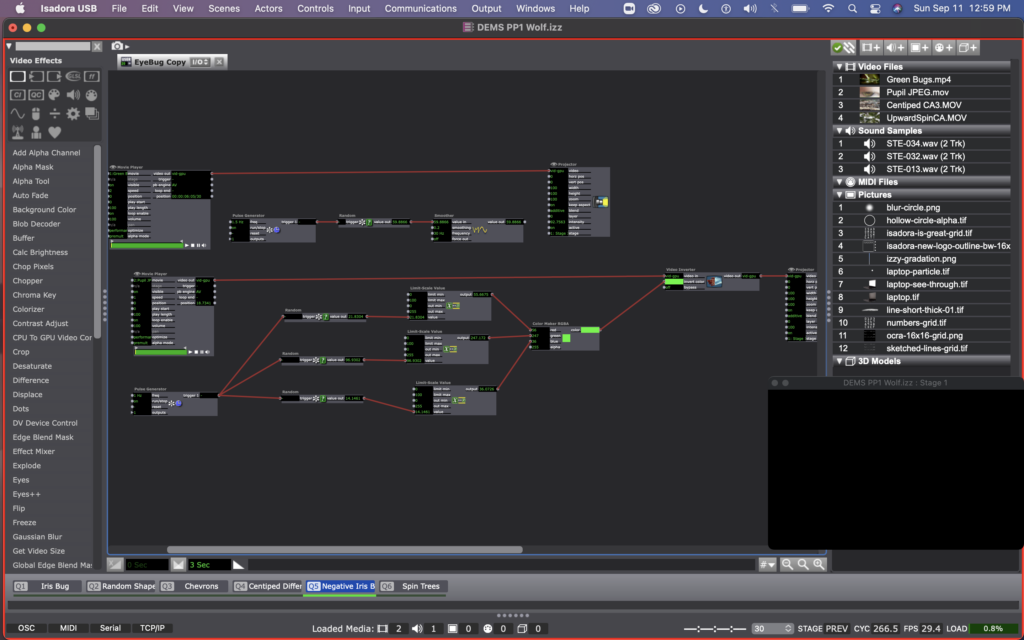
For scene 6, I have two video layers happening. One is simply a movie player and a projector, looping a video I took while spinning and looking up at the sky in the middle of the redwoods this summer. I wanted it to feel a little more disorienting, or even to make it feel like there was some outside force here, so I added a picture player and used the blurry circle that Mark included in the guru sessions. I used a random wave generator, limit-scale value, and smoother on the projector zoom input to make the blurry circle grow and shrink. Then I used a wave generator and a colorizer to have the circle change between yellows and blues.
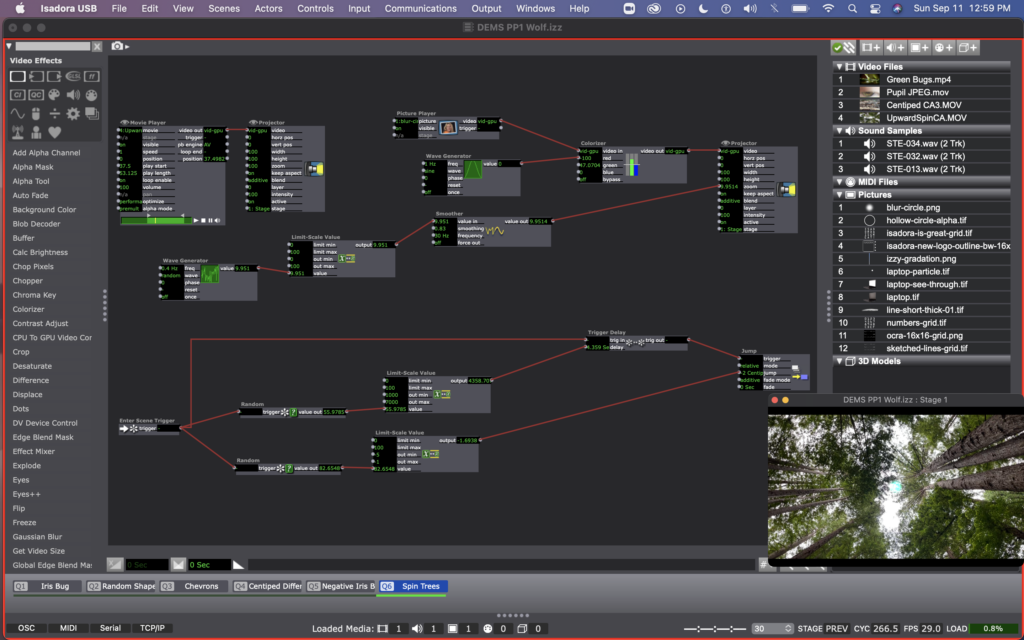
Here’s a video of what it ended up looking like once complete:
I enjoyed sharing this with the class. It was mostly just an experiment, or play with randomness, but I think that a lot of meaning could be drawn out of this material, though that wasn’t necessarily my intention.
Of course everyone laughed at the sound bit that started with “Oh shit…” – it’s funny that curse words will always have that affect on audiences. It feels like a bit of a cheep trick to use, but it definitely got people’s attention.
Alex said that it felt like a poetic generator – the random order and random time in each scene, especially matched with the voices in the sound files made for a poetry-esc scene that makes meaning as the words and images repeat after one another in different orders. I hadn’t necessarily intended this, but I agree and it’s something I’d like to return to, or incorporate into another project in the future.
BUMP: Seasons – Min Liu
Posted: September 4, 2022 Filed under: Uncategorized Leave a comment »I’m bumping Min Liu’s cycle 3 from last semester. I was drawn to this one because it seems as though this project gave the audience an experience of interacting with a digital reconstruction of a natural environment. I’m not sure I would do it in the same way, but this is the type of experience I’m hoping to create for my project. Having leaves fall in response to the participants’ movements (sensed by the Kinect) made for a responsive environment – and I think was a nice way to make the digital environment responsive without the aesthetic becoming too digital/non-natural. I’m hoping to brainstorm some ideas like this one – how can I use programming systems to manipulate imagery of the natural environment so it seems as though the environment is responding as opposed to a digital/technological system responding?