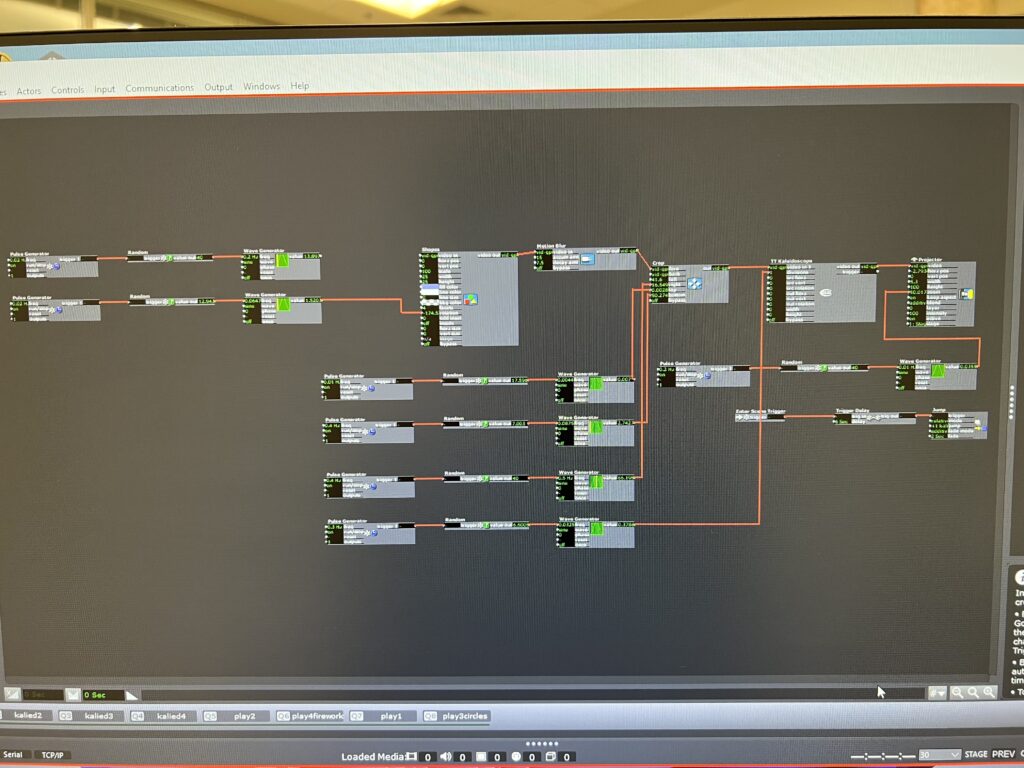
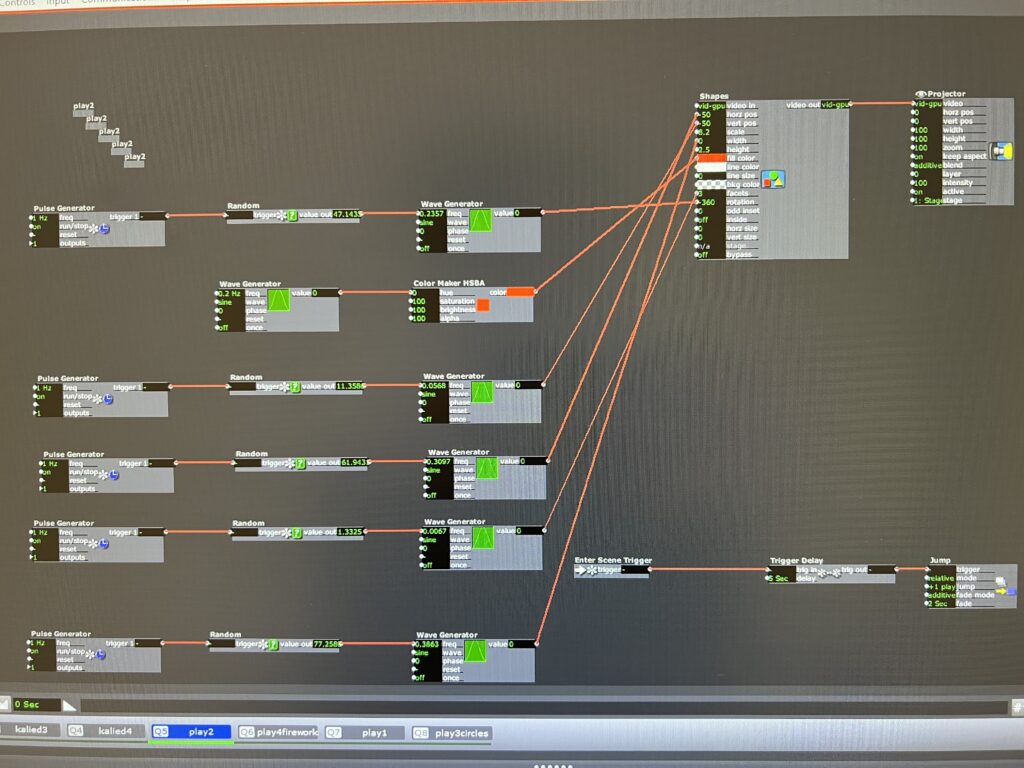
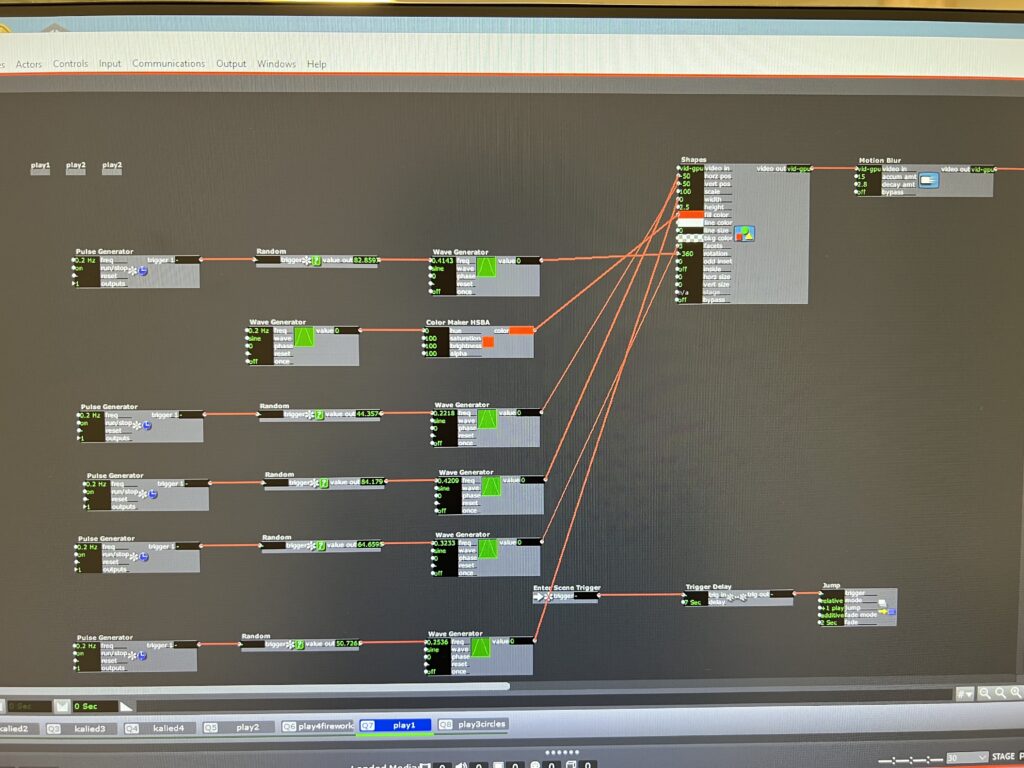
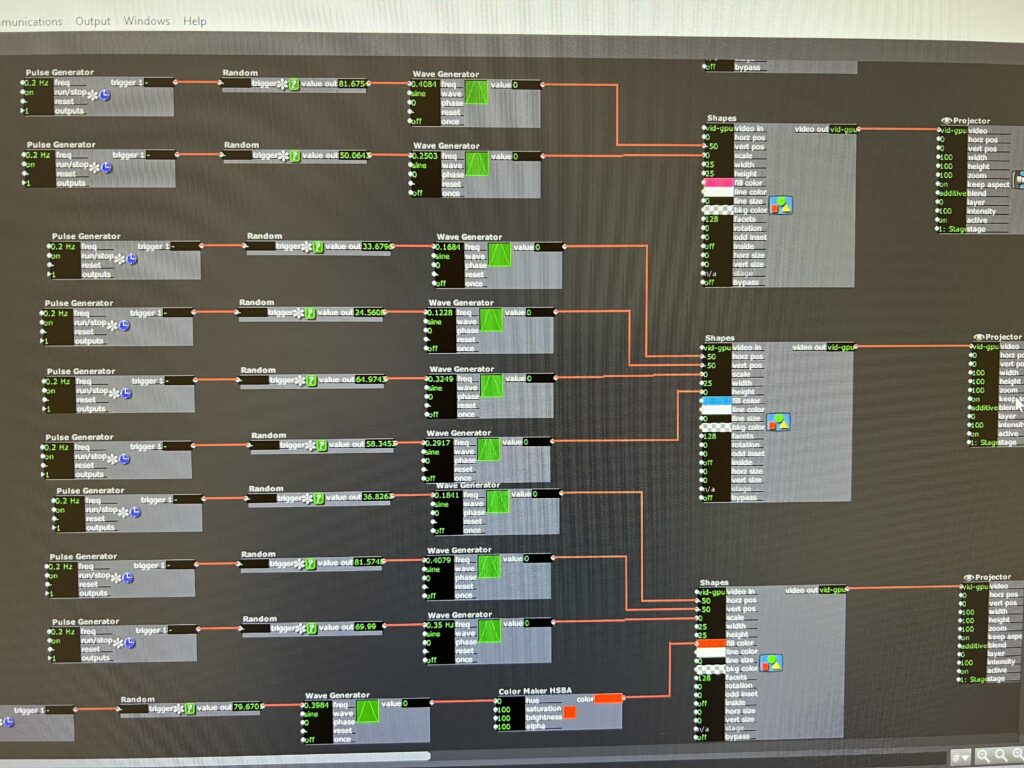
Stars Kaleid – PP1
Posted: September 9, 2022 Filed under: Uncategorized Leave a comment »For this pressure project, I wanted to take the time to play with the actor kaleidoscope++, practice triggering randomness and scene jumping, work on how to grow and expand an image smoothly and add videos into the patch.
Unfortunately, about 2 of the hours I spent working with my personal video I didn’t end up using because Isadora didn’t like the codec and I didn’t realize it in time. Isadora eventually just started freezing and not registering the video, and occasionally crashing.
After I gave up on trying to keep working on the video issues, I returned to the scenes where I had played with different shapes to create textures and images. Because I liked how the video gave the kaleidoscope a lot of movement, I added wave generators to the shape and crop actors to give the same kind of effect.
Even though there were hair pulling moments and I had to ditch some of my work, I still enjoyed the process of just connecting different actors and trying different number patterns to see how it affected the image. I ended up playing so much with the star that when I was asked how I did it, I couldn’t remember.
Right now, Isadora feels endless and limitless and intimidating. I’m grateful for this project just to give me time with the software in a low stakes way so I can experiment and begin to feel more confident. Keeping a clean interface seems to help my brain out as I’m working, so my goal is to not get into the habit of connecting actors every which way.
As I was building this patch, I was dreaming of how the body could be incorporated. I was imagining sketches and snapshots of hands, eyes, ribs showing up in the kaleidoscope as it transitioned randomly. For the next time, I will probably not use as much randomness. I liked it, but I craved a little more structure towards the end. Working with the kaleidoscope also got me imagining infinity loops, so I’m hoping to play with something like that in the future.
PP1: The Backrooms Teaser
Posted: September 8, 2022 Filed under: Uncategorized Leave a comment »
Inspiration and Background
Those of us who enjoy horror and creepy stories all know the name Creepypasta. For those of you who may be unfamiliar with the term, Creepypasta is used as a catch-all term for horror stories and legends that are posted to the internet. These stories can often be found on many forms of social media, and some have been adapted into short films or even video games.
The Backrooms is a popular Creepypasta story that discusses and explains the existence of liminal spaces hidden in our world. These spaces, often referred to as “levels”, are seemingly infinite non-Euclidean environments with twisting hallways and never ending tunnels. The lore itself is expansive, and allows for people to write their own levels into existence (as of writing this there are 2,641 entries on the Backrooms Wiki) . But a sinister and unexplainable evil resides in this dark and haunted place. It’s said that every level of the Backrooms houses a unique entity that is almost always out to get you; this concept and story mechanic has been used to create short films and media related to the original Backrooms Creepypasta. And so the infamous Backrooms: Found Footage movie was born, a short film by Kane Pixels that tells the story of a man that fell into the Backrooms and has to escape and survive the horrors within. This short film has almost 39 million views on YouTube, and is said to have launched the worldwide trend of Backrooms content.

My Experience
Now that I’ve bored you with my inspiration behind the project, I’ll talk a little about my process for the first pressure project and truly my first encounter with Isadora. I started out with the goal of making something with vintage/retro vibes. There’s something about the sound of old computers and VHS players that fascinates me, and I decided to make a little experience that uses that style.
I started by imagining my little corner of Creepypasta lore; I pictured this experience running on a very old computer in a small unsuspecting corner of a museum. A dimly lit, room with a single chair would allow for guests to be immersed in their surroundings. The computer at the center would be playing my start screen (pictured above), waiting for someone to walk by and take a seat. Once the experience starts, they would be shown clips of found footage from the first adventurer into the backrooms (clips taken from the original short film Backrooms: Found Footage by Kane Pixels) The clips would end abruptly when the footage shows our main character pushed into oblivion by a large and haunting entity; the computer cuts to black, and you’re faced with a blue start-up sequence and boot noises:
Sidenote:
I cut the following keyboard input section from the experience I showed in class due to difficulties with the text draw actor (more on that later). Because the goal was to create a self-generating patch, I ended up making it jump to the next scene after the boot-up video played out. If I had required the viewer to click the escape button it would no longer be a self-generating patch.
The input screen hums in front of you as you hear a repetitive analog beeping, waiting for you to press the escape key.
Do you do it?
You hesitate for a moment… and then *click*.
The next thing you know, this horrifying clip is playing in front of you…

Gotcha! Yes, unfortunately since we only had 5 hours and were trying to keep the element of surprise for as long as possible my goal was to build up this creepy lore and finally troll you with Never Gonna Give You Up. The video had the reaction I was going for; audience members were puzzled at the ending, wondering where the heck this video came from.
In addition to their comments on the final part of the experience, my classmates also had comments on how the story was intriguing but hard to piece together. While I was aiming for disorienting and confusing, I was also aiming for fear, and I expected at least a jump or two from one of the scarier parts of the found footage clips. No one jumped, but they did mention it was slightly unsettling!
Note to self: Make the next one scarier
What I Would’ve Done with a Little More Time
If this had been a full-length project, I would’ve spent more time onboarding the viewer into the world of the Backrooms and thinking about the physical manifestation of the project. The ideal scenario for the experience would’ve been some sort of wall-projected environment combined with a creepy old computer. And after you pressed the escape key, I would’ve transported you to the Backrooms, and done my best to scare the hell out of you with a more immersive experience featuring camera tracking and interactive content.
Process and Obstacles
This was the first creation I made with Isadora, and it was certainly a challenge since I’m a 3D artist by trade that’s used to a viewport and polygons. However, since I was familiar with node-based systems, I was able to pick up Isadora fairly quickly and start experimenting with my own ideas.
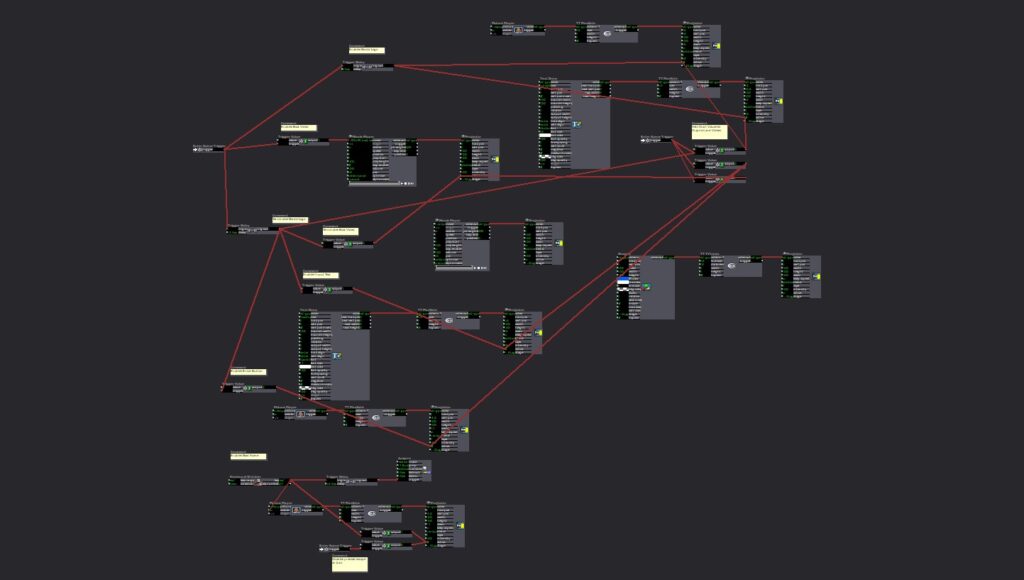
One of my biggest obstacles was triggering videos and transitions. I came up with a system that used trigger delay and trigger value actors to create a faux-sequencer that took care of video layering and playback. Then Alex told me the method I created was great, but that there was a way easier way of doing it!
Another obstacle that I encountered in the minutes before presentation was when one of my text draw actors mysteriously stopped working. The actors were there, and the connections were correct because I had tested the experience at home and it looked great. But for some reason, when I loaded my project on the PC at ACCAD, this one specific text actor was just not showing up. We later found that others had been running into this issue, and that it might be a hidden bug with this specific text actor.
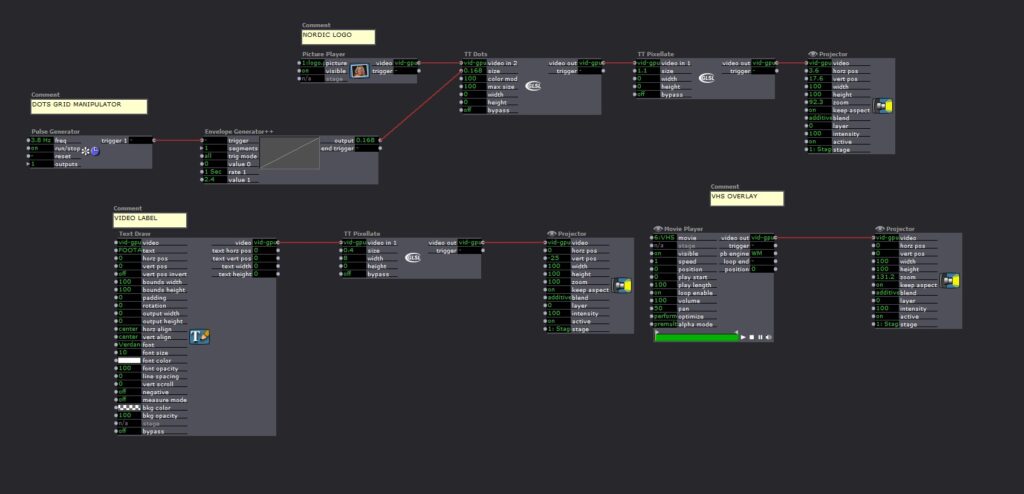
My favorite part of the project was figuring out ways to layer distortion and aging to make the experience look as old and vintage as possible. By using the TT Dots actor in tandem with TT Pixelate I was able to get some really cool effects.

Conclusion
My heart lies in the style of vintage pixelated VHS tapes and the found footage genre. I absolutely loved getting to play with creating a dated interface on a modern computer, and finding out how to mess with our expectation of fresh and high-res images. I look forward to continuing my exploration of Isadora and hopefully getting to make more cool retro-style experiences.
BUMP: Looking Across, Moving Inside
Posted: September 6, 2022 Filed under: Uncategorized Leave a comment »I picked Benny Simon’s final project because I was drawn to the concept of adding depth to pre-recorded content and through doing that examining different ways we can experience a performance. The installation seemed very engaging as people seemed to enjoy how their movements were translated onto a screen together with other pre-recorded dancers.
I am interested in exploring similar methods for my project since I would like to experiment with ways to inhabit virtual environments by using projection mapping and motion tracking. I think this was a very interesting way to make participants feel like they were a part of this virtual scene while physically moving around and having fun in the process.
I wonder what role the form on the screen of a person dancing plays in engaging with the pre-recorded video content as one? Is the lack of representation in the while silhouette beneficial for that and how would that change if the projection was mirroring participants as they are?
BUMP: Maria’s leap Motion Puzzle
Posted: September 5, 2022 Filed under: Uncategorized Leave a comment »I chose Maria’s Leap Motion puzzle project because it reminds me of the “Impossible Test” that were featured on gaming sites I visited as a Kid. And the idea of using the Leap Motion as a faux button is really cool!
BUMP: Seasons – Min Liu
Posted: September 4, 2022 Filed under: Uncategorized Leave a comment »I’m bumping Min Liu’s cycle 3 from last semester. I was drawn to this one because it seems as though this project gave the audience an experience of interacting with a digital reconstruction of a natural environment. I’m not sure I would do it in the same way, but this is the type of experience I’m hoping to create for my project. Having leaves fall in response to the participants’ movements (sensed by the Kinect) made for a responsive environment – and I think was a nice way to make the digital environment responsive without the aesthetic becoming too digital/non-natural. I’m hoping to brainstorm some ideas like this one – how can I use programming systems to manipulate imagery of the natural environment so it seems as though the environment is responding as opposed to a digital/technological system responding?
Bump: Tara Burns – The Pressure is On PP1
Posted: September 1, 2022 Filed under: Uncategorized 1 Comment »This pressure project showed both an intrigue with certain actors that wanted to be explored, and a knack for abstract storytelling. As I was watching it, it felt like Tara was playing and enjoying what the program can do. Although I’m sure it wasn’t all kick and giggles, there was an ease about how the design traveling through its timeline. I liked the use of color and liveness, and I found a few new actors that I want to learn about.
I appreciated what she said about desired randomness… or randomness in a way you want it. How do you make specific randomness?
Cycle III – Bar: Mapped by Alec Reynolds
Posted: May 2, 2022 Filed under: Uncategorized Leave a comment »The Experience
Cycle III was the final presentation stage of the project. Bar: Mapped is a demonstrative example of an elevated nightclub bar experience that would be regarded as a special attraction at venue. The purpose of this project was to demonstrate a pragmatic and engaging use case of projection mapping. Below I will walk you through the intention behind the Isadora side of the experience:
- A user will order a drink off of the themed menu. The drink will be prepared and then the bartender will press the drinks button on the iPad kiosk which will trigger the desired scene in the bar area.
- The iPad communication works through a TouchOSC communication protocol over a network that both the client running Isadora and the iPad are on.
- When the Isadora patch receives the input from the iPad, a trigger is sent from the TouchOSC actor to a jump scene actor. There are six total scenes in the patch representing the Main bar scene and then one scene for each of the six themed cocktails.
- Once on the desired scene there are four main pieces of media that are playing:
- A large video is mapped to the screen
- A smaller video is mapped to the box that the bottles rests on
- The smallest video is mapped to four out of five of the liquor bottles. The fifth bottle is a mapped image of itself. The design intent behind this was to highlight the main ingredient in their specific cocktail
- A sound effect that compliments the theme is played
- After the large video reaches the end of its loop, the movie player actor triggers a scene jump back to the Main bar scene and a new drink can be ordered.
Lessons Learned
Isadora is an extremely sensitive and temperamental software. For my Cycle III performance, I unfortunately was not able to present my work in the fashion that I intended to. Due to what I believe was a performance issue with the high variability in resolution and codec, Isadora would reliably crash each time that I tried opening a stage into full screen mode, or mapped any bottle. In order to salvage a performance, I was able to loosely map the Main bar scene bottles and fit my small stage to full screen. TouchOSC still worked and demonstrated the triggering well, but nothing was mapped.
Beyond complications with Isadora, I was able to have a fundamental appreciation for how much skill Projection Mapping takes. Being able to manipulate the projector angled lighting onto a physical asset is nothing short of an artistic craft. Just scratching the surface of complexity with small curve bottles, I now have a deeper appreciation for some of the large scale projections, the likes of which you see at Disney and Large Municipality Events.
If I Had To Do It Again
If I were to do this project again there are a few steps I would take to ensure that the performance was more successful. The primary change is that I would ensure that all my media and content was formatted the same so that Isadora could process it without crashing. Next, I would try to make the experience understood better that Bar: Mapped is in its own room / section of the nightclub and that the music that is heard is bleed over from the main dance floor. In tech rehearsal the music was prepared such that it was at a quieter volume and was only playing from two speakers in the rear of the performance space from the perspective of Bar: Mapped. During the Cycle III performance, the music was blaring and playing from all channels making it sound like the room itself was the nightclub. The final lesson I have learned is that in an environment like that, the people that want to be there are going to have fun, and the people that got dragged there, well its them that you have to work the hardest on to ensure they have a good time. My hope would be that the extra layer of immersion that the projection mapping provides, would fascinate the unsteady patron and keep them drinking and dancing.

Cycle 3 – Seasons – Min Liu
Posted: May 2, 2022 Filed under: Uncategorized Leave a comment »Based on the second cycle, I further developed the experiential system for children to learn about geography & season in this final cycle. I built a spherical interface with makeymakey, copper tape and conductive paint. Participants can touch specific locations on the globe and trigger different interactive environments featuring local geographical and climatic characteristics.
I searched for countries and places that is now (late April) in Spring, Summer, Autumn and Winter. I choose Tokyo (Japan), Amazon rainforest (Brazil), Mount Maceton (Australia), and Yellowknife (Canada) correspondingly and marked them on the globe. I used Kinect as input device this time and it worked much better than Webcam. In the autumn and the winter scenes I had created in the previous cycle, participants can interact with falling leaves and snows. I built the other two scenes this time. In the Spring Tokyo scene, the Kinect tracks people’s head and Sakura flowers will fall right above participants’ heads on the screen. In the Summer Amazon rainforest scene, rain falls on people and bounces off. I will explore more interactive visual effects in the future. I also added audios to each scene which made the experience more immersive. Here are the scenes I built in Touchdesigner:


In the final presentation, I was happy that participants explored the physical globe and engaged in interacting with different virtual environments both individually and together. They said the experience was fun and educational and they didn’t even notice that they were learning. Also, children will be excited about this experience. It’s a very COSI thing.
Here are some points to improve about this system. First, there needs to be some ambient light to make people brighter and more detectable, thus improving the sensitivity of interaction. Second, the spring Tokyo scene is too bright, and the flowering interaction is too slow. Third, there can be some explanations for participants to know that they are experiencing the weather in the area in current time.
Here is the recording of the experience:
Cycle # Patrick Park
Posted: May 2, 2022 Filed under: Uncategorized Leave a comment »For the last cycle I prepared a play space where the music evolves by positions or it activates one shot samples. The song I composed plays throughout the entirety of the experience. If the audience goes closer to the camera the voice switches from regular to pitched up voice. Vive versa, when the participant is moving away from the camera, the singing switches back to normal. In the mid spaces there were triggers that played notes in the scale the song was written in. In front there are trigger that turned on echos and delays (although it did not activate this time). In the back there are 808 bass drums and a snare sound. My plan was to create “out of bound” area where every track would be playing in reverse. This did not happen because making sure that the main interactive functions took a long time to actually work. In this cycle there were more excitement and urge to interact in the room than last couple cycles. Making sound triggers to interact together with a song is a fun idea. Hope to keep developing this.
Cycle 3 by Jenna Ko
Posted: May 1, 2022 Filed under: Uncategorized Leave a comment »I used Isadora and Astra Orbbec for an experiential media design where a tunnel zooms in and out as the audience walks toward the projection surface.
The tunnel represents my state of mind where I mentally suffer from the news of the Russian invasion of Ukraine, the Prosecution reform bill in Korea, and marine pollution. The content begins with an empty tunnel. As the participant walk toward the projection surface, the news content fades in. I wanted to articulate my hopelessness and powerless feeling through the monochromatic content that fills the tunnel. As the participant walks towards the end of the tunnel, hopeful imagery of faith in humanity fades in. The content is in color, contrasting with the tunnel interior.
Finally, I was able to implement the motion-sensing function with my media design. If I were to do this again, I would set up the projector in a physical tunnel for a more immersive user experience.
