Cycle 3: مہمان – Mehmaan (The Guest)
Posted: May 8, 2026 Filed under: Uncategorized | Tags: Cycle 3, touchdesigner Leave a comment »The Score
For Cycle 3, I knew exactly what to work on: the harmony between the particle effects and the floor pattern, the fact that there needed to be a visual feedback of the body in some way or form, and that the body needed to leave a mark. The last thing on the checklist came from the concept that the guest or the user should change the space by being in it, because that’s how mehman-nawazi works. The house holds the warmth of whoever was there.
So Cycle 3 added the trace. A silhouette of the users’ body’s that follows them in color-shifting cache through the space and stays for a few seconds. The colors cycle and change as the trace lingers. It’s not a shadow, it’s more like a very colorful version of a heat map of being in a specific position. The users can see where they were. This also caters to the visual feedback of the body that was missing in cycle 2.
The experience also expanded outward. Two additional scrims on the sides of the space were used to carry the partcile system of the falling petals. These were not interactive, just ambient. Just to give a feel of an enclosed space. The front screen remains interactive. There was also a screen at the back – showing everything that was going on in the space.
Resources
- TouchDesigner
- Orbecc depth camera for body/blob detection
- My trusty laptop
- Top down projector, and the rug
- Projection screen
- Motion Lab
- Tripod mounted Camera
- Scrims
Process and Pivots
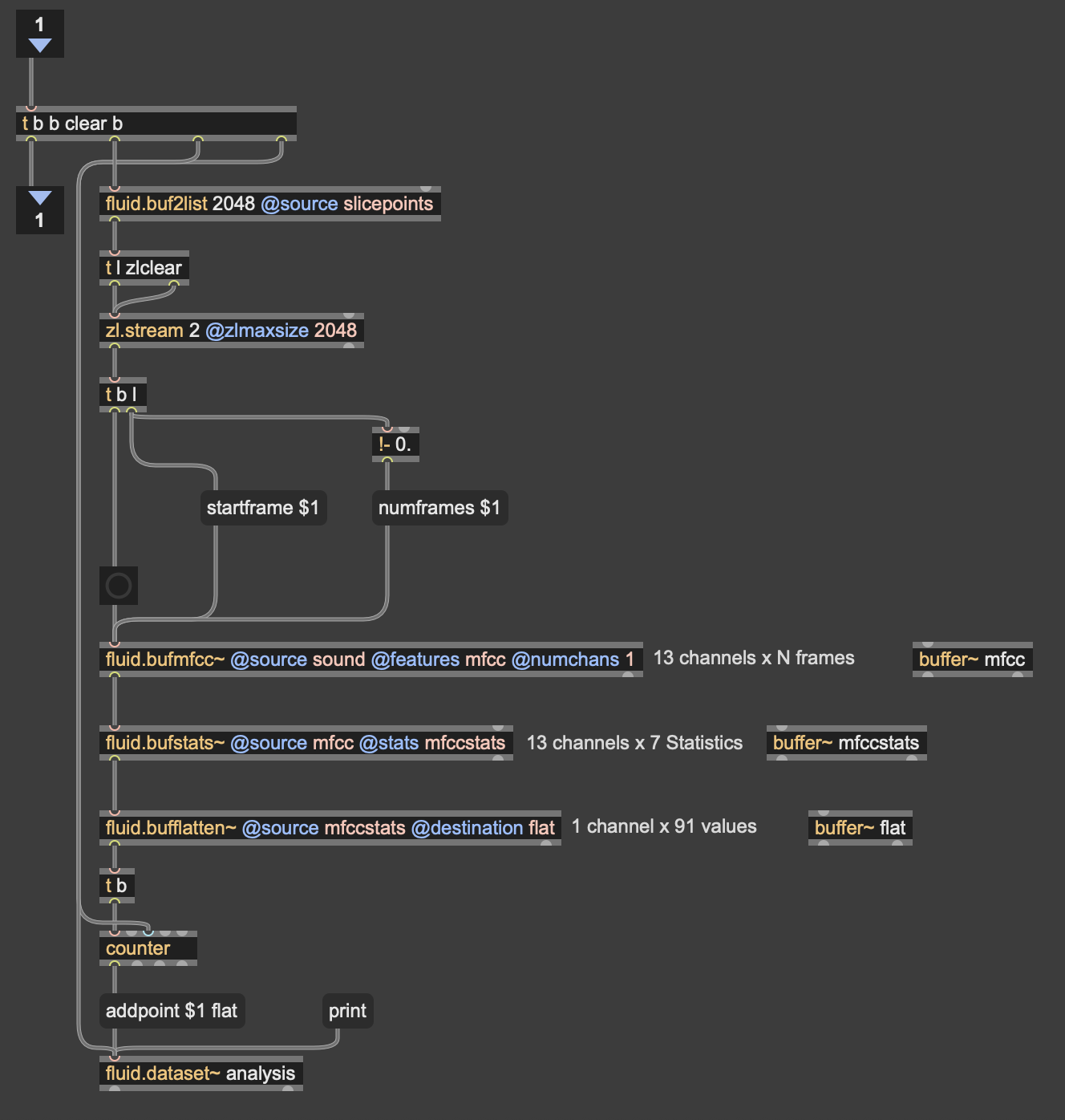
The silhouette trail was the main new challenge. It uses a cache and feedback system inside TouchDesigner. Since there was only one orbecc available, the problem was to create accurate silhouettes using something else. This led me to the nvidia background top – which is surprisingly accurate. The body mask from that was put in a feedback loop with a cache top that makes the silhouette decay slowly. I also added a time-based color ramp function which makes the color change for each frame. The result is a trail that shifts through colors as it fades. Adding such dynamic colors to the particle system was also meant to act as a bridge between the zen particle system and the fast audio reactive floor projections. The floor pattern from Cycle 2 was slowed down.
The two side screens were simpler. They were just additional outputs fed from the same petal particle system but without the optical flow input. They made the space feel larger and more continuous. This meant that the users would no longer be just standing in front of a single screen. The environment was meant to wrap around you them, with screens all around.
What Worked, What Didn’t, What I Learned
What worked: I went in first, interacted with the system, and then invited everyone over to the space. I didn’t say take turns or anything. I just mad ethe gestures for everyone to come over and they did! That was a good idea as it worked as a good ice breaker for the initial awkwardness experienced in the previous cycle. Everyone was in the space from the get-go. The silhouette trail also worked great! It was an immediate visual feedback that was easy to understand. Everyone moved and watched themselves leave marks. They stood in one spot, did all sorts of gestures, danced around, twirled, and there was also a train happening at some point. So the whole experience was very very social. It was like watching people play in a fun playground.
I was told that the addition of the two side screens made the space feel complete in a way the single-screen version didn’t. It felt like an environment enveloping you. Lou mentioned that even though the side screens didn’t have any interactions, it was nice to go up to them and see their projections on your body.
What I’m still thinking about: The silhouette and the petals exist together but I dont know, there isn’t really much of an iinteraction between the two. Which is okay, BUT it would be nice if they could effect each other in some way. That feels like the next thing to do. Also for the previous cycle, I had tried to do a position based trigger. So I dissected the circular space of the rug in 4 quadrants, and depending on where a user is, it triggers some visuals on the screens. I couldnt get it to work but I keep thinking what if about it. I would also love to explore some physical interactions triggering some events in a cool physical-digital way.
What I learned across all three cycles: I started off by trying to make an AI listen to the user and ended up making a space that receives the user instead. These are two very different orientations, but I learned throughout the process that making a good experience requires you to pay attention to even the most seemingly-insignificant interactions and feedbacks of the users. Things that don’t even feel like findings when they’re happening are sometimes the most useful data you can collect. It’s just very easy to miss them because we (atleast me – I dont speak for everyone) are looking at the system instead of looking at the people.
Pressure Project 3: Love Letters from Home
Posted: May 7, 2026 Filed under: Uncategorized | Tags: Pressure Project, Pressure Project 3, touchdesigner Leave a comment »This project was created as a purely audio experience, a three-minute piece with no visuals. It was meant to be cultural storytelling, but in the process of doing that, it became something very personal. Honestly, I’m not even sure if I made it for anyone other than myself.
The interaction is built around proximity form the camera and the system. Using Mediapipe inside TouchDesigner, the system estimates the participant’s distance from the camera based on the space between their shoulders. That distance is then mapped into three separate zones: near, mid, and far. Each zone triggers a different audio sequence of a minute long, creating a shifting soundscape as you move through space. The interaction is very simple but it gets complex in what it means.
The zones are not just meant to be spatial, I also intended them to be emotional. The farthest zone holds the ambient sounds from back home. It contains sounds of a place I have very fond memories of, Liberty Market in Lahore. It’s full of life, voices, interesting characters, and movement. It holds the ambient chaos and the unique life of a place that feels familiar when you’ve lived inside it. Underneath it also runs the sound of a dhol, a traditional drum from South Asia which is often played during celebrations and festivals. The recording is from my wedding, which turns it into something both public but also secretly personal.
The middle zone moves closer to the system and my life, into family. My parents asking if I’m okay, telling me to take care of myself, giving blessings in the everyday way they do. There are also scattered pieces of time spent with my siblings, just being together, being absurd and being just us. There is also snippets of my dad telling us a ghost story around a bonfire. All of them are just small moments when they’re happening, but they kind of accumulate weight as time passes, especially now that being together like that is rare.
The closest zone is the most intimate. It has audio of me and my husband. Snippets of our vows, pieces of our wedding song, voice notes he sent me from long distance of him singing to me, and also us singing together. The songs are in Urdu, which is our mother tongue. So music in this case, is not just background. It’s part of how we stayed close across distance before we could be in the same room.
The piece doesn’t guide you or explain itself. You move, and it responds. What you hear depends entirely on how close you choose to stand, how long you stay, whether you move toward something or away from it. That felt like the right way to design this piece because that’s how memories also work: existing in a very non-announcing sort of a way.
I asked someone else if they would like to perform the piece (I didn’t feel like putting myself out there and I thought I would end up crying), and Chad volunteered. That did not go exactly as planned and it annoyed me because he was trying to figure out how the system worked and all of its interactions, and in doing so, he missed half of the experience. I realized I shouldn’t have told someone else to give a performance for something as personal as this project in my stead, because it wasn’t a puzzle meant to be figured out.
So I did what I had to, in order to fix the situation: I performed it myself. I may or may not have cried while creating this, but performing this made me so happy and I felt relieved to have done it “properly”.
The most surprising part was that even people who didn’t understand the language still felt something. Lou told me they got teary-eyed. That meant a lot to me. It showed that the piece wasn’t just about language or culture in a literal sense, but about something deeper, and also obviously about the performance since they did mention that they could tell how much this meant to me while seeing me perform.
If I develop this further, I want the zones to be less blocky, and to be more fluid and abstract, even floating around like memories. But even as it is, I really like this piece because of how much it means to me, and it does feel complete in a different way.
Cycle Two: A 3D Movement-Based Sound Explorer
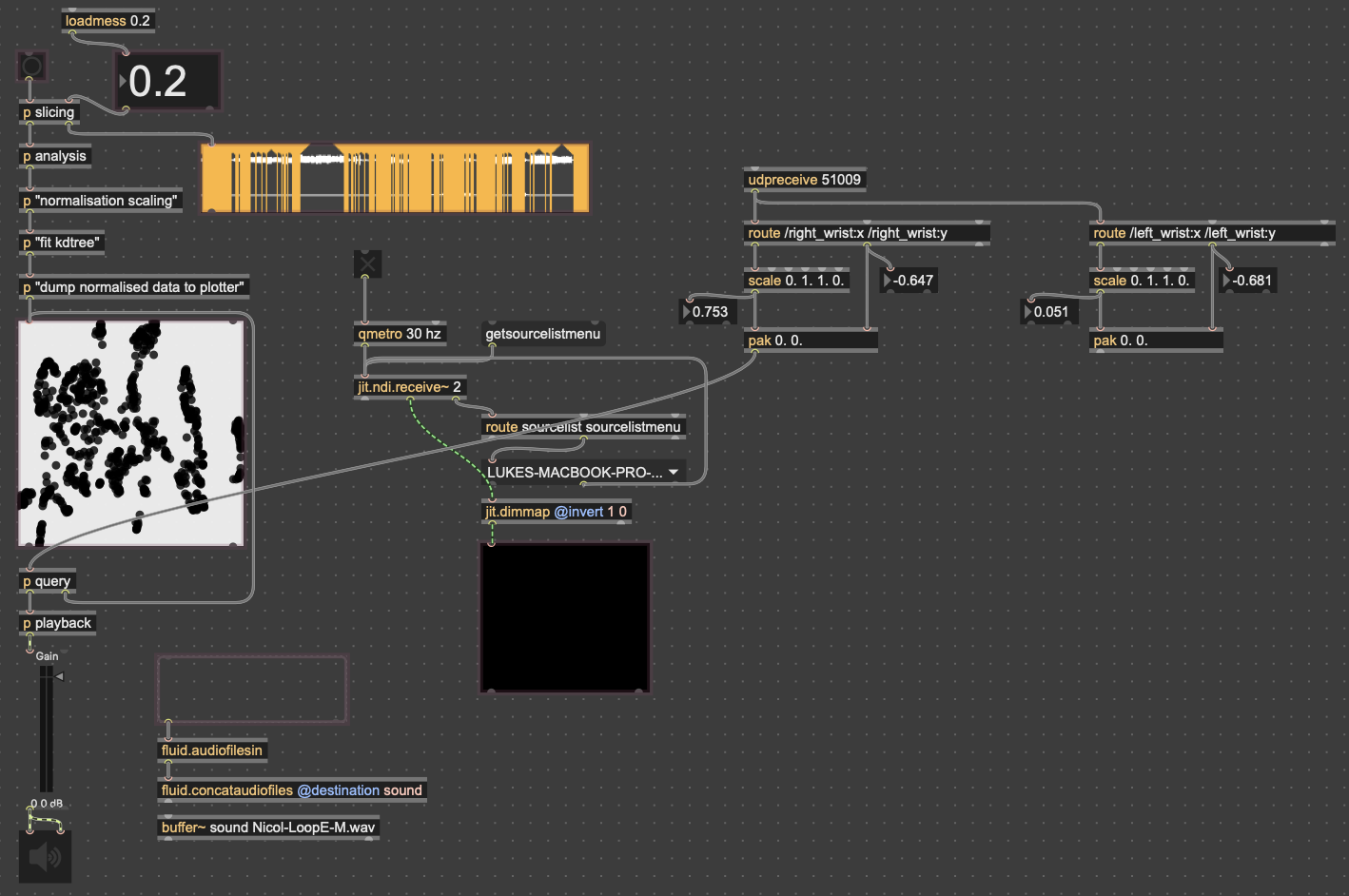
Posted: May 5, 2026 Filed under: Luke Buzard | Tags: Cycle 2, FluCoMa, MaxMSP, MediaPipe, touchdesigner Leave a comment »Going into cycle two, I immediately knew that I wanted to take the ideas I had done in 2 axes of movement in cycle one and translate it to 3D. In order to do this, I needed to rework the analysis portion to plot all the samples in 3 dimensions, as well as figure out a new way for the user to see their movement within the corpus of sounds. For several days, I tried to do the analysis section on my own, but found myself unable to figure out how to plot them in a 3D space as I’m not great with Jitter, Max’s visual package. However, just about when I was getting ready to give up, I found someone who had already done exactly what I was trying to do.
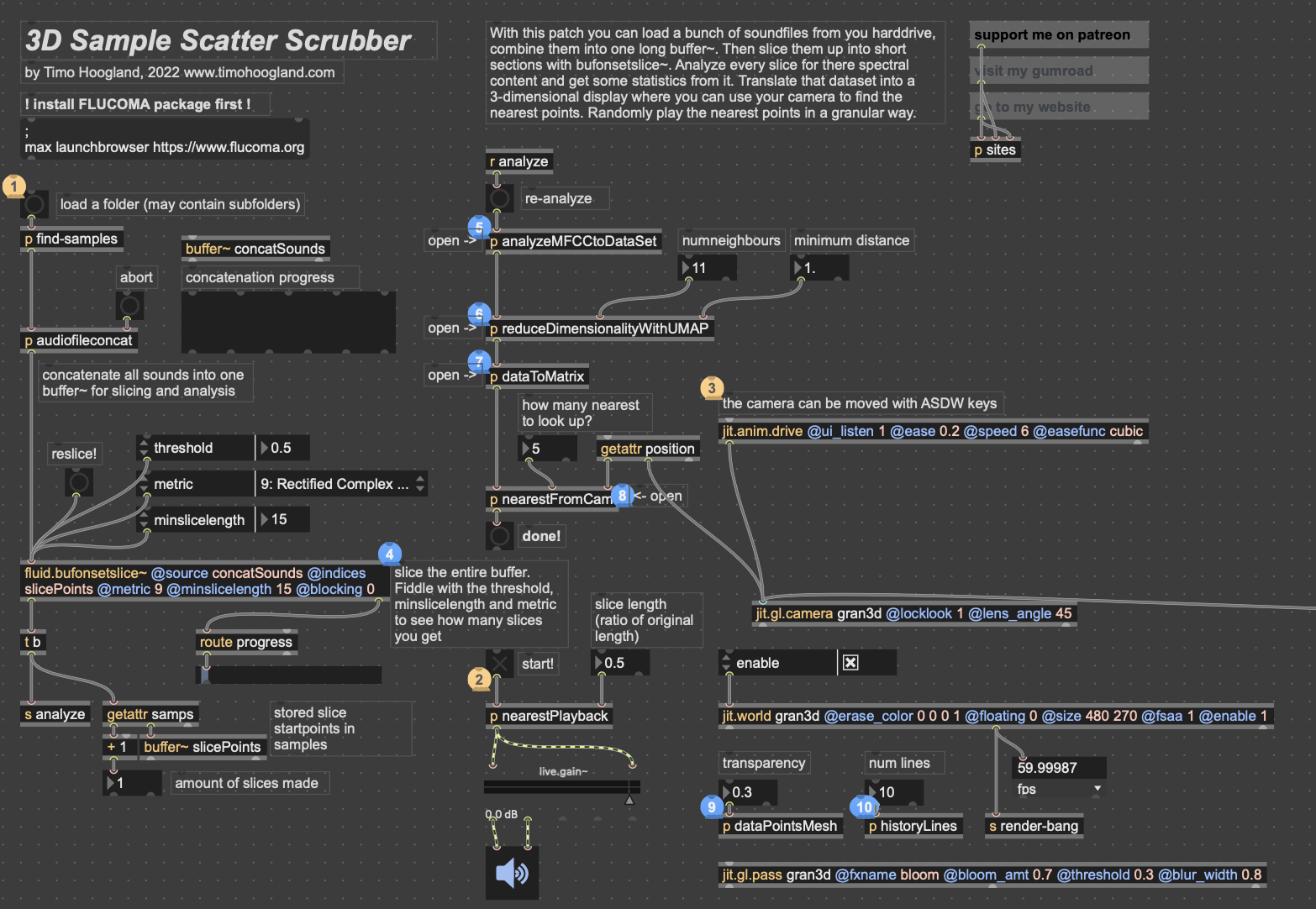
I won’t get too in-depth on how this works. But in short, it reduces the MFCC analysis data to 3 dimensions, as opposed to 2 in cycle 1, unpacks all that data into a matrix with 3 dimensions, and then that matrix data is used to generate an OpenGL environment with all the samples plotted in a 3D space. Then, depending on whatever point the camera is closest to in the Jitter window, the sample that correlates with that point is played back. This camera, however, was driven with WASDQZ, so I had to implement a new system of control that allowed this 3D corpus explorer to interface with the Google Mediapipe data I was receiving from TouchDesigner. I did this by scaling the data to the 3D space, smoothing it out some, and sending it a as list into the position attribute of the jit.gl.camera object.
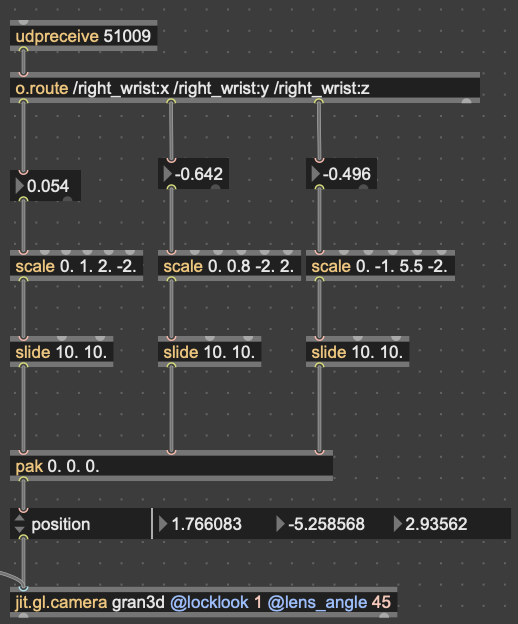

Zoom-out of the 3D corpus space, each dot represents a sample; dimmer dots are deeper on the Z-axis
Results
Unfortunately, I don’t think my vision for this cycle translated to reality as well as I’d hoped it would. One of my biggest issues was that I left on an option that locked the camera to (0,0,0) in the space. This caused a major decorrelation between the movements of anyone using it and the movement in the space. Everyone seemed to struggle with “navigating” the corpus space much more than in the 2D iteration. Once I got rid of this attribute during our discussion afterwards, people understood what was happening better right away. I think the camera was also just a little glitchy since MediaPipe isn’t the *best* at detecting depth, which caused it to jump around wildly. I think if I were to continue with this 3D idea, I would have to incorporate a depth sensor in some way so that all 3 dimensions are accurate.
In my first cycle, I also included the MediaPipe landmark camera feed in the projector image as a sort of monitor for movement. In this one, I made the decision not to include it, as I’d hoped the movement in a 3D space would translate more intuitively to the user. However, I was really surprised that most everyone actually missed its presence. I think the playfulness of the little dot stickman moving around on screen must have provided a nice counter to the cacophony of sound. For this reason, I made a point to include the landmark skeleton in the final version.
Here’s a short recording of Alex using the system. As you can see, it was not very precise. Additionally, something in the analysis created a lot of sample points with that shrill high pitch sound that frequently plays. I don’t know where this came from, but it taught me to always check the samples when I’m working with tools like FluCoMa.
While this cycle was a bit of a fail in meeting the goals I had, I think it actually gave me a chance to step back afterwards and examine what the goals I wanted to achieve with these cycles were. Out of all of them, the largest was to create a group experience. This setback caused me to really narrow in on that idea for the 3rd cycle, which I think worked out much better in the long run.
Cycle One: The Movement-Based Sound Explorer
Posted: April 13, 2026 Filed under: Uncategorized | Tags: cycle 1, FluCoMa, MaxMSP, MediaPipe, touchdesigner Leave a comment »As I began thinking about what I wanted to make my cycles about, I found myself gravitating towards a question I had previously been interested in when beginning to work on my senior project at the beginning of the year: How might technology allow for the creation of new modes of musical interface, where the relationship between audience and performer is almost entirely dissolved?
My primary resource was Max/MSP, as I know it best of all the computer music softwares, and I find it very useful for the development of new ways of making music.
Going into this cycle I knew one of the central resources that I could use to help me answer this question was Google MediaPipe–a real time motion capture software that uses webcam input as opposed to dedicated hardware/software that requires mo-cap suits. This allows for systems which anyone can easily interact with, even without knowing how the system works or what each mo-cap landmark is controlling. I handled this part of my patch in TouchDesigner, as the Max integration of MediaPipe has some difficulties I don’t have time to get into here.
My main goals for this cycle were to create an interface to interact with sound that was fun, interesting, but also left room for potential emergent behavior when left in the hands of different users.

The second major piece of software I used was the Fluid Corpus Manipulation (FluCoMa) toolkit for Max/MSP (also available in SuperCollider and Pure Data). This toolkit uses machine learning software to analyze, decompose, manipulate, and playback a large collection (or corpus) of samples. I initially chose this piece of software as one of its modes of playback is a 2D plotter which can map two different aspects of the sample analysis on to an X and Y axis. I thought this would be a perfect interface for MediaPipe control as the base 2D plotter uses mouse input, which I found to be detrimental to using it as an “instrument.”
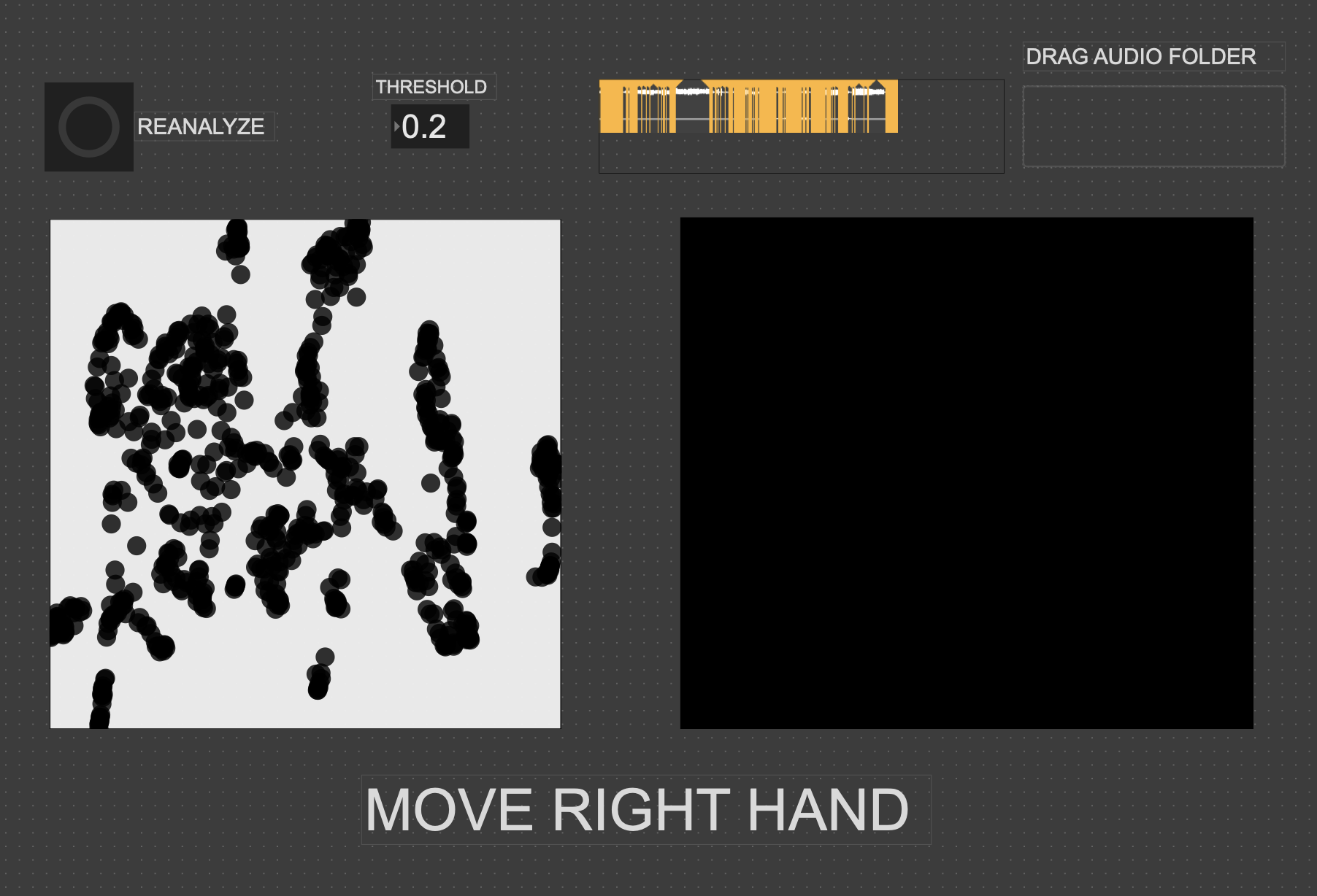
I had initially wanted to expand the idea of the 2D plotter to a 3D one, as I felt being able to interact with the patch in a 3D space would be much more natural. However, I found expanding the logic to work in 3 dimensions was a much more difficult task than I’d thought, so I decided to stick with the 2D plotter for this cycle.
Results
I thought that I was mostly very successful with the goals I set out to accomplish. Everyone wanted to try out the patch, which I thought was a testament to the “fun” and “interest” aspects of it. The controls were also quickly picked up on, which was a goal of mine, as I’m interested in systems that audiences can interact with regardless if they’re conscious of the mechanics of that interaction or not. I was most interested to see how different people had their own unique ways of interacting with it as well. Chad, for example, was really trying to make something rhythmic and intelligible out of it, while others were going all over the place, or looking for specific sounds.
Some missed opportunities that I want to expand on in future cycles is the use of the Z dimension in controlling the playback of samples, as well as the use of multiple limbs to control playback. As you can see in the video, users were somewhat restricted in how they could control the patch by the Z direction not doing anything, as well as the fact that only the right hand could trigger sounds. By expanding this idea to 3D, instead of two, and allowing for the use of multiple limbs, I think it’ll give people more freedom in how they interact with the corpus of sounds.
This was the first real project I’ve done with FluCoMa, and thus I learned a ton about its mechanisms, particularly the storage of non-audio data in buffers. This is a concept used a lot more in environments like SuperCollider or Pure Data, as Max has some other objects for storing that kind of information. However because of the way the machine learning tools in FluCoMa work, it needs to store all of the information it may need in RAM. This was also the first project I’ve done sending OSC data between different apps on my computer, which had a bit of a learning curve as I discovered OSC data sends as strings, instead of floating point numbers. This didn’t create any real difficulty, as the conversion took no time, but it did make me aware of an important aspect of using OSC (particularly with Max, as certain objects process strings/floats/integers differently).
Cycle 1: The (bad) Friend
Posted: April 7, 2026 Filed under: Uncategorized | Tags: cycle 1, touchdesigner Leave a comment »The Score
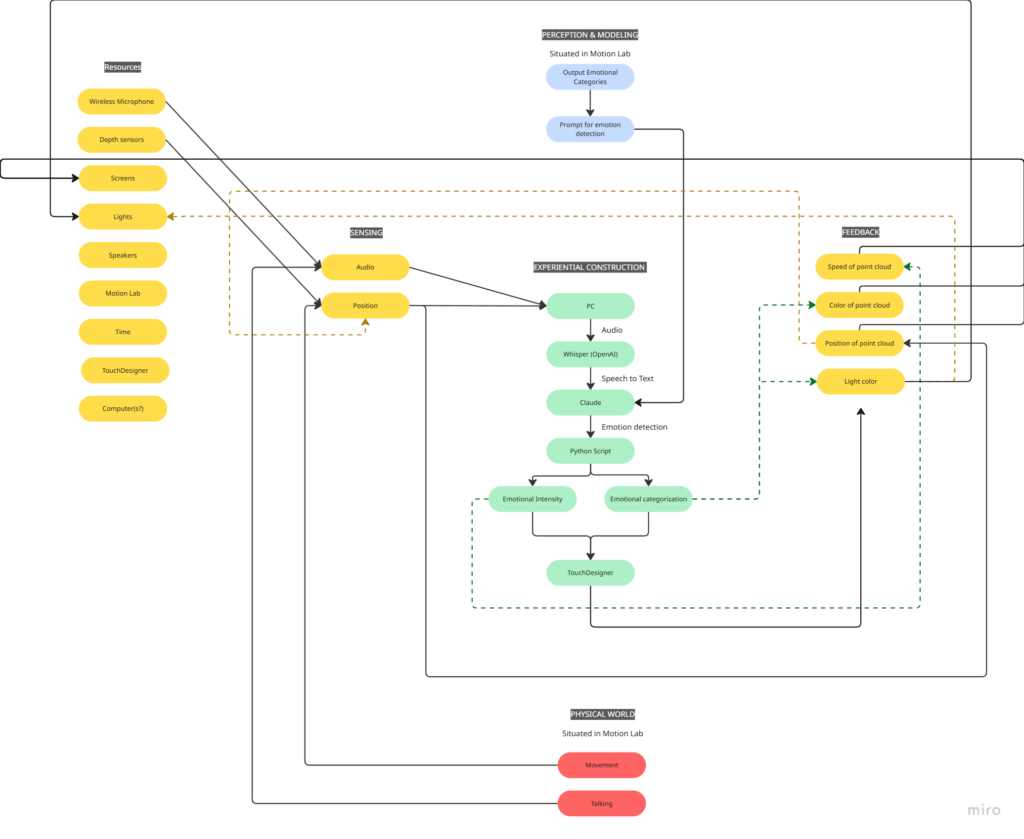
My idea for this cycle was simple (or atleast it seemed so in my head): make an AI-powered interactive experience where the user shares a space with an AI ‘presence’. It lives on a screen, but its there for you and it listens to whatever you have to say – or dont have to say. The score: a participant enters a space, speaks naturally, and the environment responds to the quality of what they shared through a particle system. No text output, no voice back. Just the space changing around them. The framing I gave participants was: “this is a friend you can talk to.” That framing is what became the main problem.
Resources
- TouchDesigner for the visual/particle system
- Python + PyAudio for microphone input
- OpenAI Whisper for speech-to-text transcription
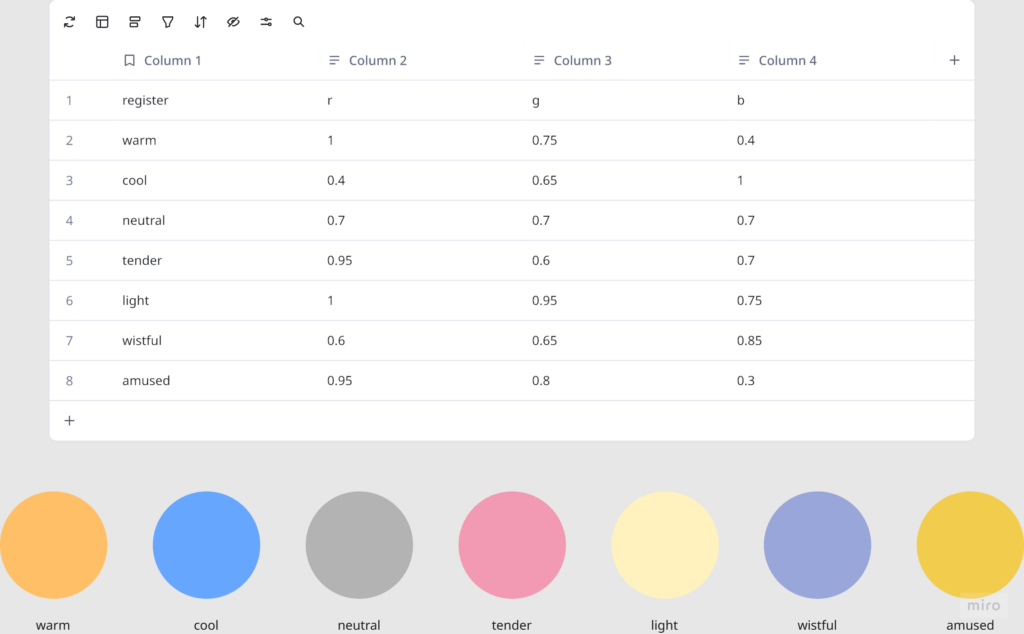
- Claude API to interpret the speech and return atmospheric parameters (brightness, movement, weight, density) as JSON
- OSC to pipe values from Python into TouchDesigner
- Orbecc depth camera for body tracking (ceiling-mounted, blob detection)
- Motion Lab
- A Michael for troubleshooting (1)
Process and Pivots
I wrote a python script that takes user input through the microphone, then uses OpenAI Whisper for speech-to-text transcription. It then sends the speech to claude in order to parse it according to the system prompt I gave it, which were metrics like emotional register, weight, intensity etc. The python script in turn sends these metrics to touchdesigner through OSC. Inside touchdesigner, I made table DATs that were storing the values of the incoming signals in order to apply those values to the visual system (a particle system). The values were suppsoed to effect the movement and color of the particle system.

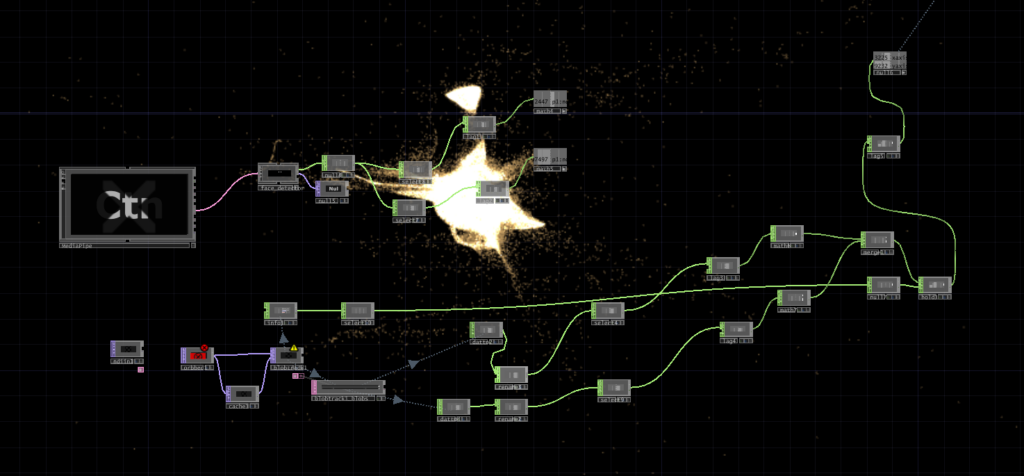
I initially built my system on MediaPipe for body tracking, but then when I shifted the system to the motionlab, I had revelations. The system worked fine for a laptop but for it to work in an open space and a big projection screen, it would need a camera directly in front of the participant’s face (and the screen) to work, which sounds horrible for an immersive experience. So, I switched to blob detection through the Orbecc ceiling camera. That took a while to get right. It wouldn’t even detect me and I couldn’t figure out why so I made the very obvious assumption that it hates me lol. Turns out it needs something to reflect off of and I was wearing all black.
The original prompt to Claude was trying to do an emotional analysis, as in read how the person was feeling and respond to that. At some point I rewrote it to just read the texture and quality of what was shared, not the emotional content. That was actually the most important design decision I made: the difference between “I understand you” and “I am here.” The particle system was jerking between states and it felt mechanical, so I also had to apply some smoothing for it to not act crazy.
What Worked, What Didn’t, What I Learned
What didn’t work: ALOT. I think apart from the framing of the system, I had not realized the amount of time I needed to properly do this. I had only gotten a limited amount of time in the MOLA so I was only able to troubleshoot the projection and not run through the whole pipeline. I did not anticipate alot of things as they went wrong the biggest example of this would be the lag. There’s bad bad latency in the pipeline (mic → Whisper → Claude → OSC → TouchDesigner) and it was long enough that participants got confused. They’d speak, nothing would happen, they’d speak again, then two responses would arrive at once. A few people got genuinely frustrated. The “friend you can talk to” framing made this much worse because it set up an expectation of conversational timing that the system couldn’t meet. Lou said it was a bad bad friend. Like one of those people who keep looking at their phone when you’re trying to talk to them.
What worked unexpectedly: The observers. People watching someone else use the system felt something – specifically, they felt empathy for the participant who was being poorly served by the AI. That observation became the most interesting research finding of the whole cycle.
What I learned: Time is the biggest resource, and you have to plan according to it. Instead of trying to force all of your bajillion ideas into the time that you have. Also, framing matters more than you think it does! Had the same system been framed a different way, I would’ve gotten away with it, but since I had framed it a specific way, there were specific expectations.
Pressure Project 2: One for All, All for one
Posted: March 9, 2026 Filed under: Pressure Project 2 | Tags: Pressure Project, Pressure Project 2, touchdesigner Leave a comment »I named my cell One for All, All for One because it is built around the idea that an individual, and communities as a whole are constantly shaping each other. The cell itself is a constan conversation between the oneself and the communal archive. It takes a live video feed and layers it over a slideshow of images showing communities and people from different parts of the world.
Then interactive sound enters the picture. A glitch effect driven by audio input levels determines how much the live video overlay fractures. The louder the audio, the more the live layer breaks apart and reveals the slideshow underneath. Alongside this, I built in an internal LFO paired with an Edge TOP to create a rhythmic pulse, something I called a “heartbeat”. Even without external input, the system works fine and feels alive.

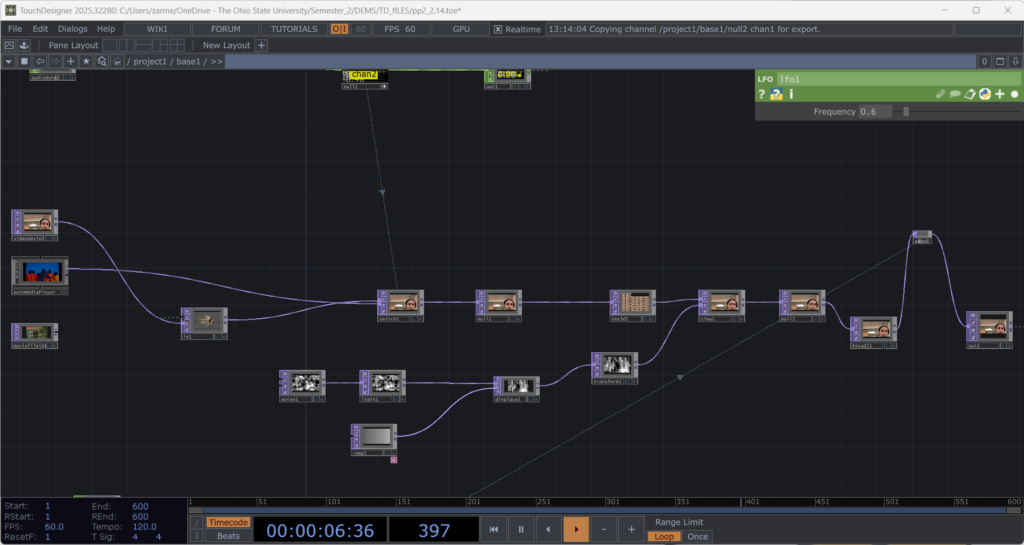
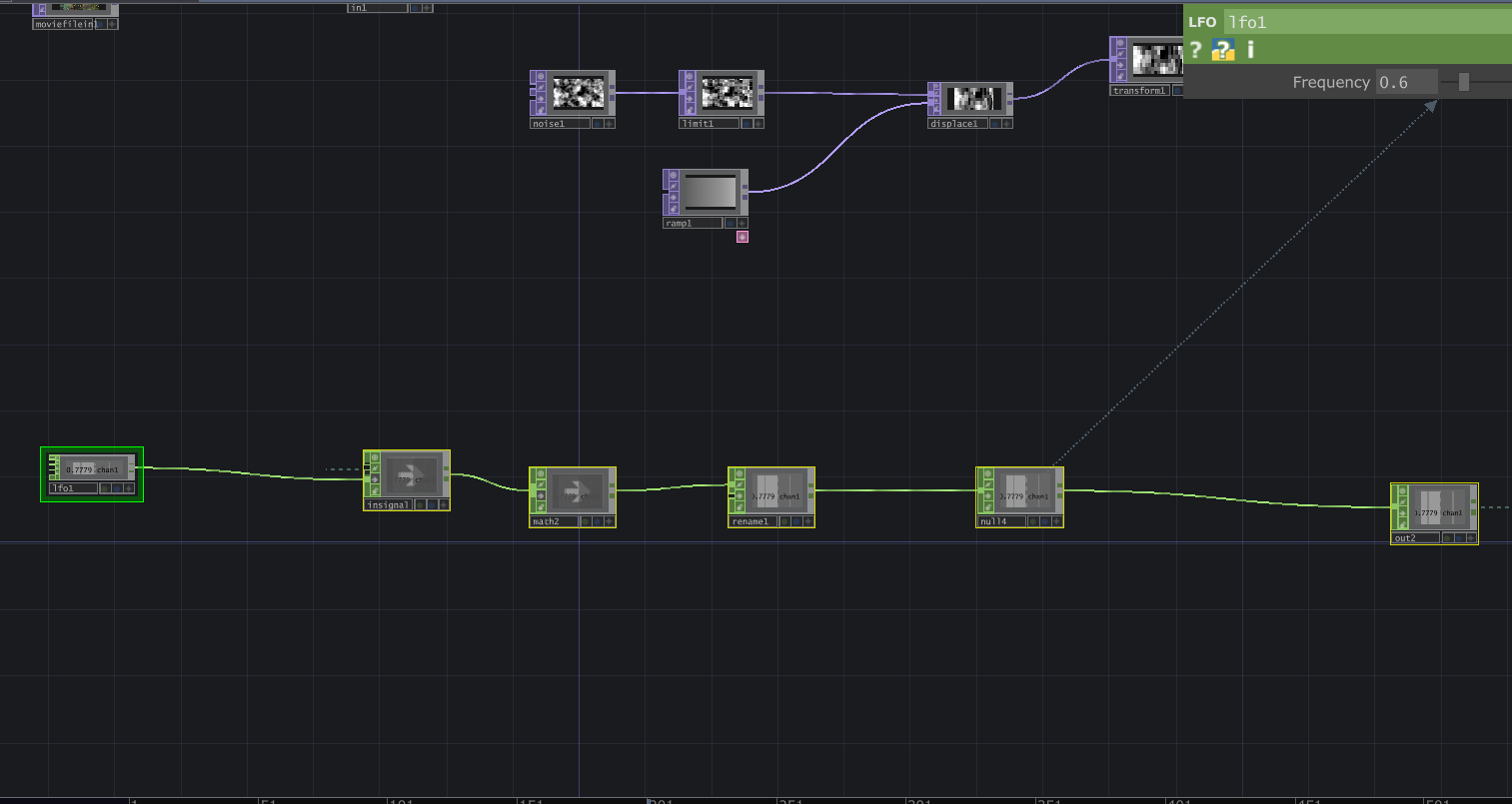
The structure is modular and layered, and honestly not that complicated. There is a live video input, and a media player (which controls the slideshow) which plug into a switch. The output of the switch goes into a glitch system, and a pulse system. Each could be replaced without breaking the overall logic. The audio input, live video input, and the signal (LFO) are designed so that they could be overridden by an external network signal as well. The cell has its own system, but it is designed to connect, following the true concept of one for all, all for one.
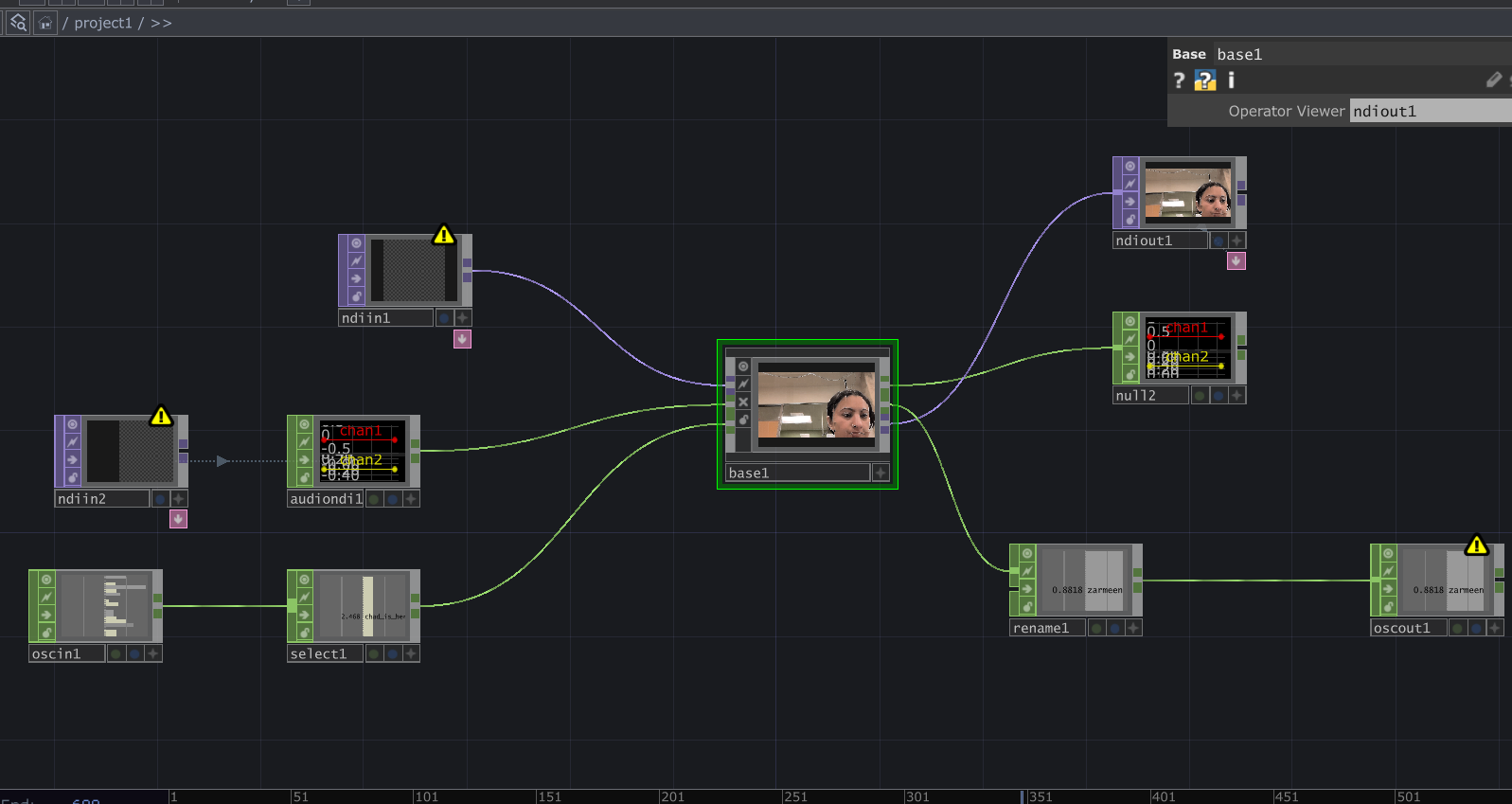
Reflection:
When all the cells assembled, things became unstable. Signals were constantly dropping and connections were dying. For a while, I thought something was wrong with my cell because nothing would show up (it was a problem with the input signals I was getting). When I finally got it to work, very interesting emergent behaviors appeared. The glitches danced to different rhythms. Video overlays ended up in very interesting stacked outputs. It was interesting because I did design my system while being aware that it had to be plugged into a bigger system. However, I did not envision the results I got during testing. What I controlled alone became either amplified or distorted by others. The network did not just combine outputs. It reshaped them. I think where my careful planning fell off was the heartbeat. I had not accounted for the fact that other cells can have signals of different types. Instead of a steady pulse, I got an irregular signal input, which changed the whole heartbeat effect. At first it felt like something went wrong. My cell was no longer just reacting to my inputs. It was reacting to everyone. That is exactly what One for All, All for One means. Each cell affects the others. Each signal influences the collective behavior. My cell had a life of its own. In the network, it learned to respond, adapt, and sometimes surrender to the collective.
Project File: pp2_Zarmeen.zip